
논문 리뷰
Deep Reinforcement Learning for Robotics, A Survey of Real-World Successes
수업 과제에서 논문 리뷰 관심 있는 것이 있어서, 가지고 오게 되었다.
1) 논문 한눈에 보기
- 논문: Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes
- 버전: arXiv v3 (2024-09-16)
- 핵심 질문:
- DRL이 실제 로봇 문제에서 어디까지 성공했는가?
- 어떤 영역은 성숙했고, 어떤 영역은 아직 어려운가?
이 논문은 단순 알고리즘 비교가 아니라, 실제 로봇 환경에서의 성과를 기준으로 DRL 연구를 분류하고 성숙도를 평가한다.
2) 논문 핵심 프레임워크
논문은 DRL 로보틱스 연구를 아래 4축으로 분석한다.
| 분석 축 | 설명 |
|---|---|
| Robotic Competency | 로봇이 학습한 능력(이동, 조작, 사람/다중로봇 상호작용) |
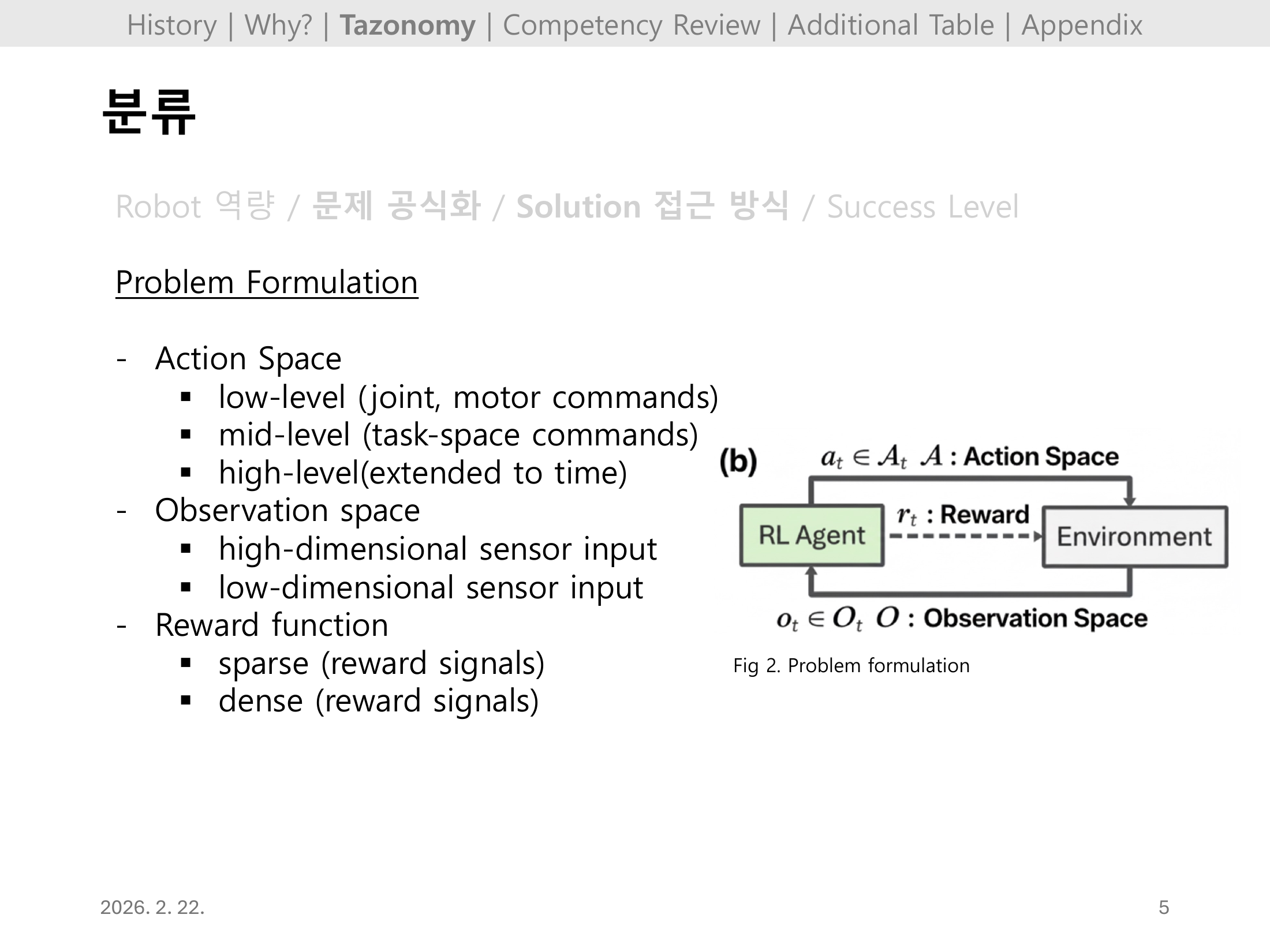
| Problem Formulation | 상태/관측/보상/행동공간을 어떻게 RL 문제로 정의했는지 |
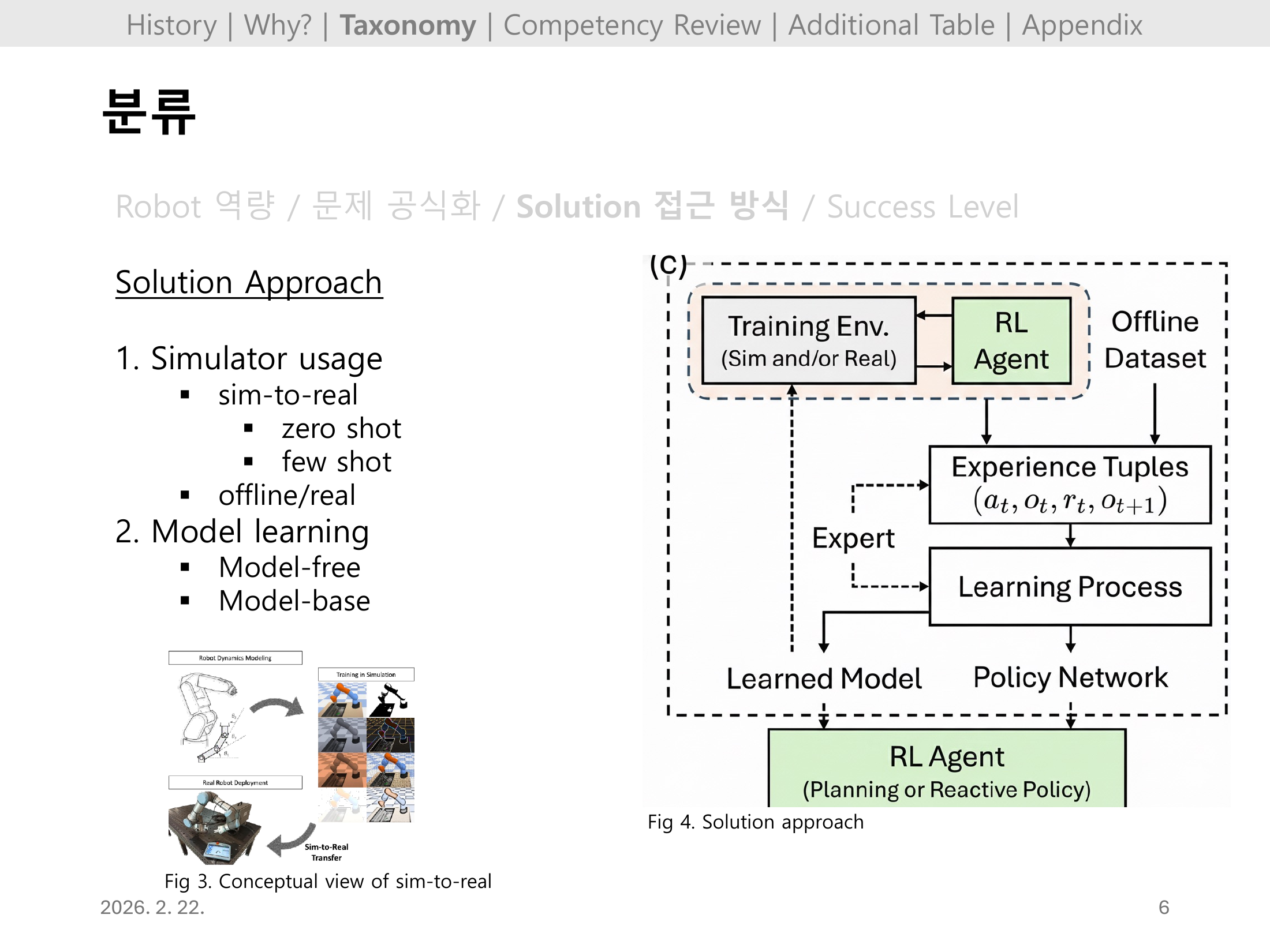
| Solution Method | 시뮬레이션 기반, sim-to-real, real-world learning 등 학습 전략 |
| Level of Real-World Success | 실험 성과를 실제 적용 성숙도(레벨)로 평가 |
Real-World Success 레벨 (요약)
| 레벨 | 의미 |
|---|---|
| L0 | 시뮬레이션에서만 검증 |
| L1 | 제한된 실험실 환경 검증 |
| L2 | 다양한 실험실 환경 검증 |
| L3 | 제한된 실제 환경 검증 |
| L4 | 다양한 실제 환경 검증 |
| L5 | 상용 제품/서비스 수준 배포 |
3) 발표 슬라이드 업로드 방식
아래처럼 슬라이드 이미지를 올린 뒤, 각 장 설명을 채워 넣는다.
- 이미지 경로 예시:
/assets/slides/drl-robot-251110/slide-01.png - 파일명 규칙:
slide-01.png,slide-02.png, …,slide-30.png - 한 슬라이드당 구성:
- 슬라이드 이미지 1개
- 핵심 메시지 2~4문장
- 내 해석/비판 2~3문장
4) 슬라이드별 설명 초안 (30장)
Slide 01. 제목/저자 소개

이 발표는 DRL이 실제 로보틱스에 얼마나 성공적으로 적용되었는지 체계적으로 정리한 서베이를 소개한다.
저자진은 UT Austin, University of Virginia, Sony AI 소속으로 구성되어 있고, 발표 범위가 넓어 이후 슬라이드의 분류 체계가 중요하다.
Slide 02. Deep RL의 기존 성공과 로보틱스 난점
DRL은 게임/추천 등에서 이미 강력한 성과를 냈지만, 실제 로봇은 데이터 수집 비용과 안전성 제약이 훨씬 크다.
즉, “시뮬레이션 성능”과 “현장 성능” 사이의 간극이 핵심 문제라는 점을 먼저 짚는다.
Slide 03. 서베이 목표와 분류 기준

이 연구의 목표는 DRL 로보틱스 성과를 능력/문제정의/해결법/실세계 성숙도로 나눠 종합 평가하는 것이다.
단순히 SOTA를 나열하는 대신, 영역별 성숙도 차이와 공통 병목을 찾는 데 초점을 둔다.
Slide 04. Taxonomy: 실세계 성공 레벨
기술성숙도(TRL)와 유사한 관점으로, 연구 결과를 “실사용 가능성” 기준으로 평가한다.
같은 성능 수치라도 어느 환경에서 검증됐는지에 따라 해석이 달라져야 한다는 메시지다.
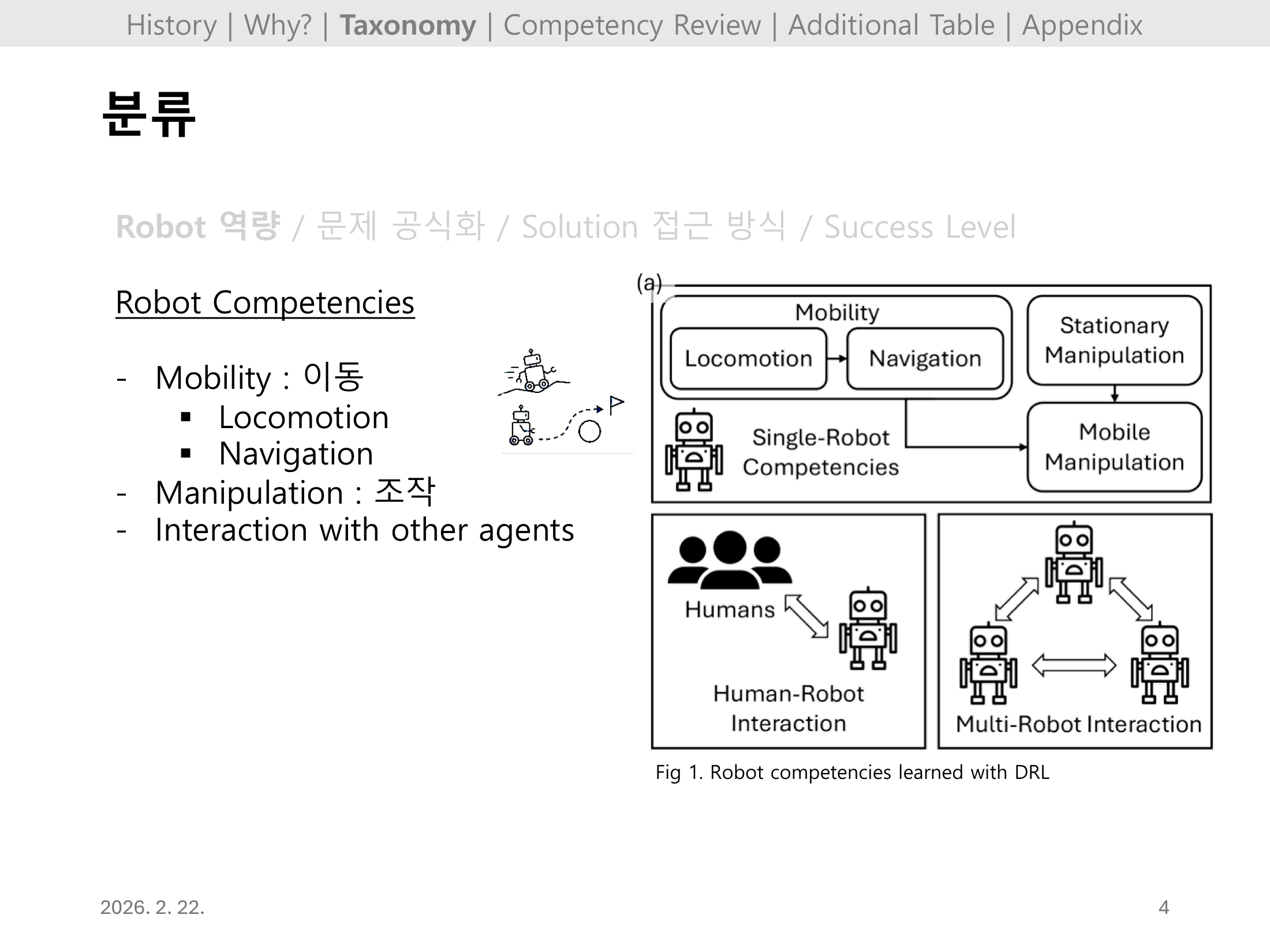
Slide 05. Taxonomy: 로봇 능력 분류
능력을 이동(Mobility), 조작(Manipulation), 타 에이전트 상호작용으로 분해한다.
이 분류는 이후 각 장에서 왜 어떤 영역은 빠르게 성숙하고, 어떤 영역은 더딘지를 비교하는 기준이 된다.
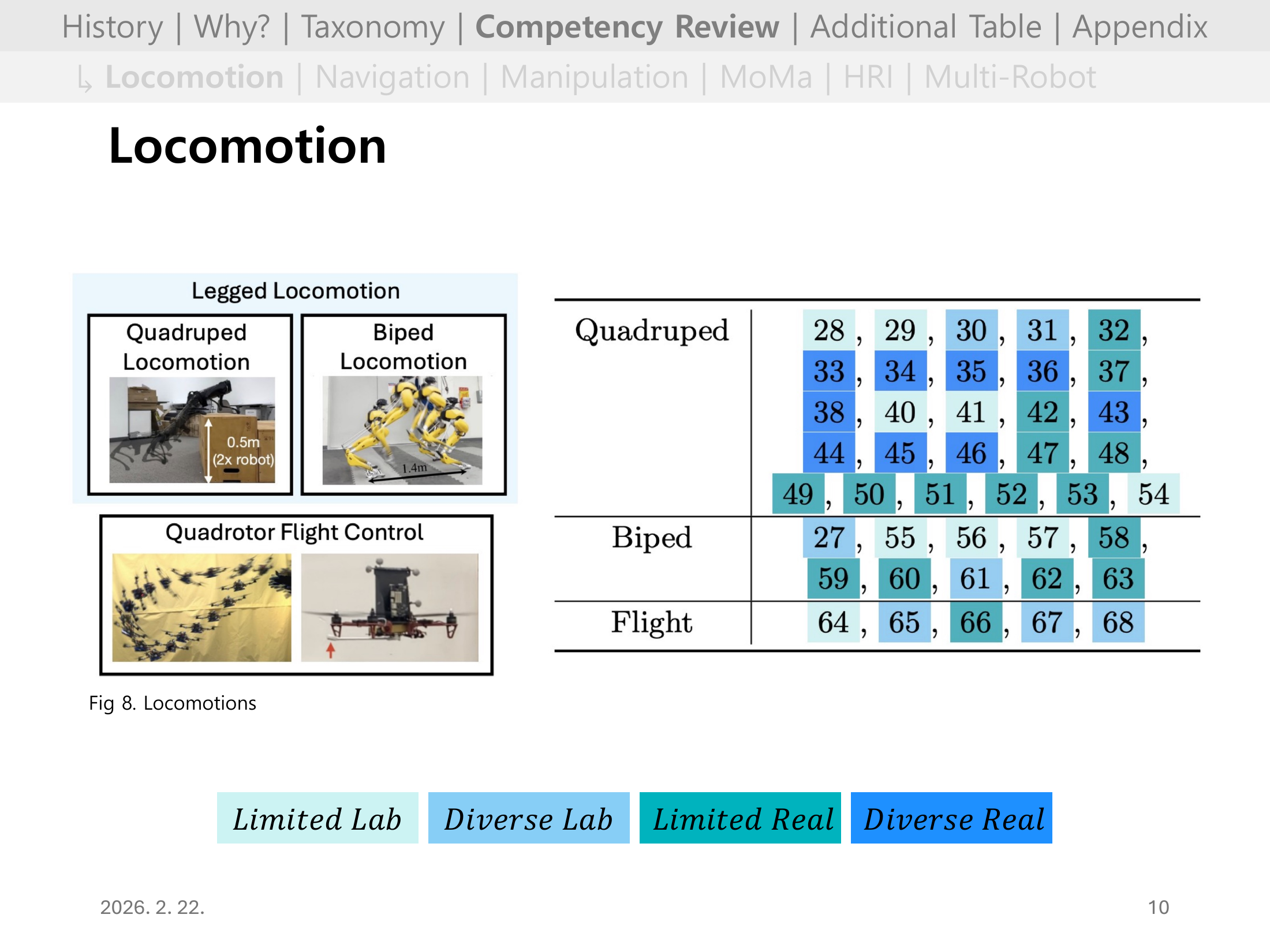
Slide 06. Locomotion 개요
이동 제어는 DRL의 대표 성공 영역이다.
특히 사족보행에서 sim-to-real 파이프라인이 비교적 안정적으로 작동한 사례가 축적되었다.
Slide 07. Locomotion 핵심 요약
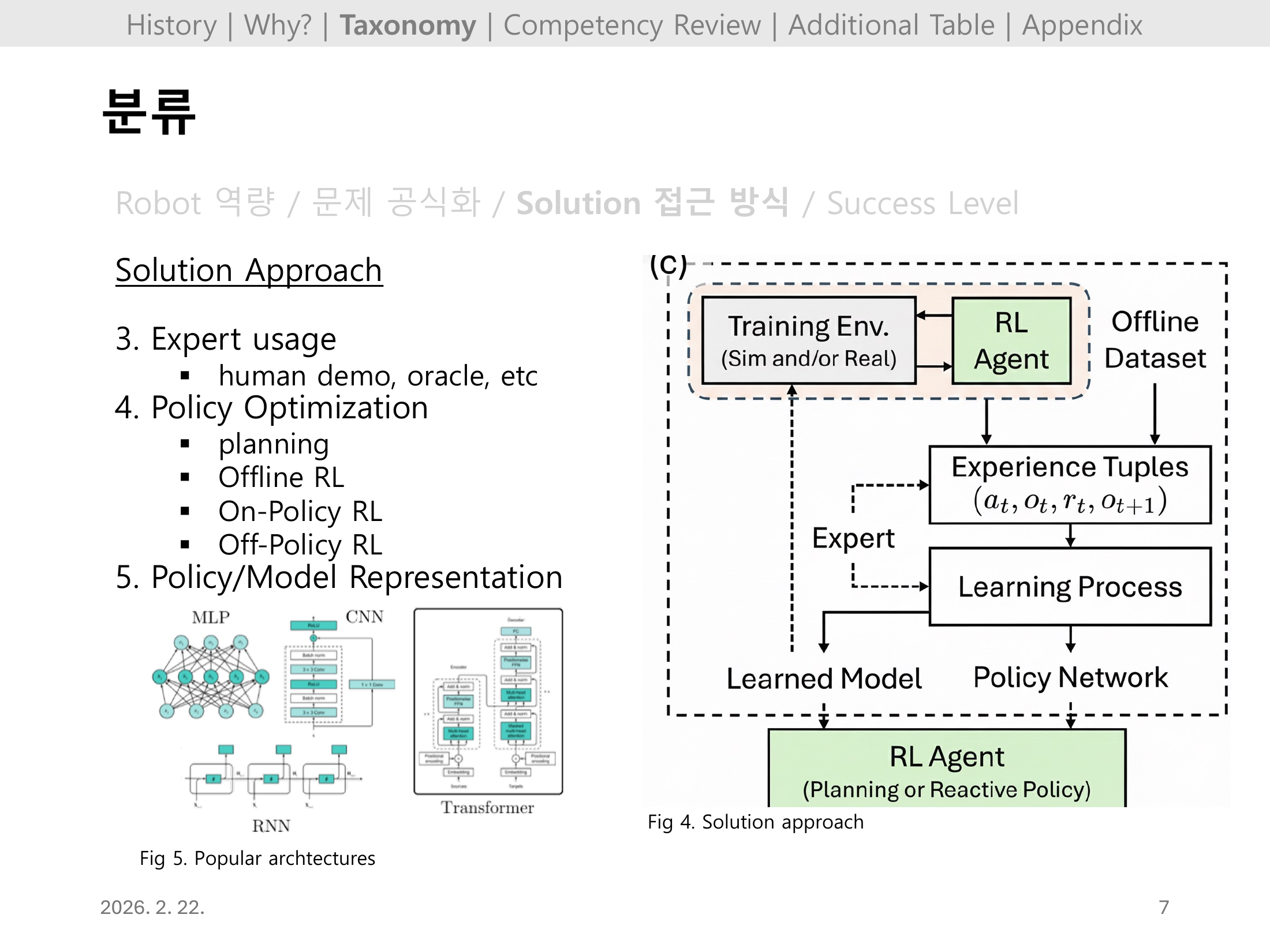
사족보행은 성숙도가 높지만, 이족보행은 동역학 난이도와 하드웨어 접근성 때문에 상대적으로 어렵다.
또한 zero-shot sim-to-real과 privileged information이 자주 쓰였고, 향후 과제는 안전하고 효율적인 실세계 학습이다.
Slide 08. Navigation 개요

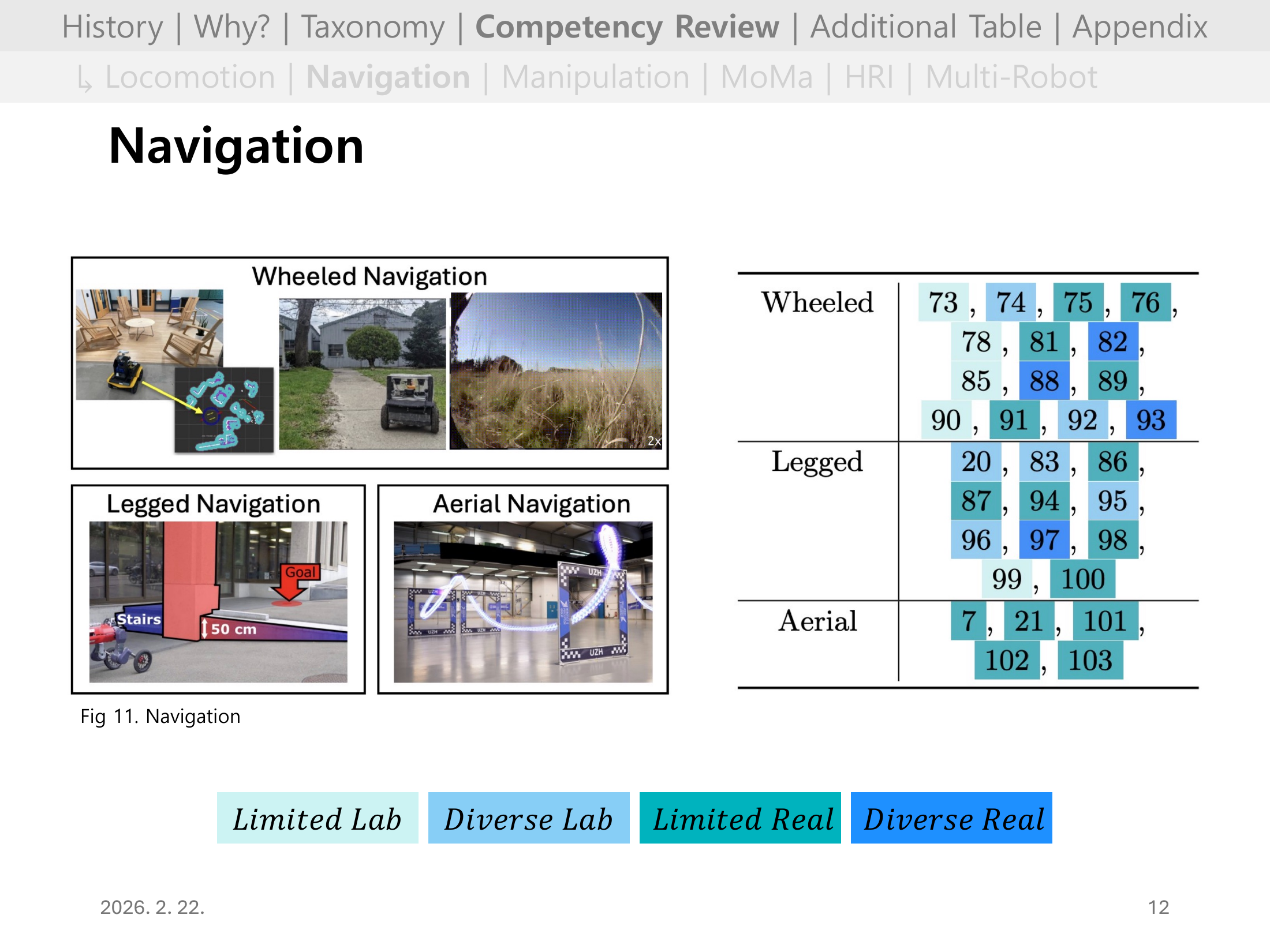
네비게이션은 실제 적용 맥락이 다양해 평가가 어렵다.
실내 자율주행, 드론, 차량 등 플랫폼별 요구 안전성이 크게 다르다는 점이 중요하다.
Slide 09. Navigation 핵심 요약

시뮬레이션에서는 end-to-end RL이 강력하지만, 실제 시스템은 모듈형 구조가 여전히 우세하다.
특히 안전이 중요한 도메인(자율주행 등)에서는 RL 단독보다 고전적 기법과의 결합이 현실적이다.
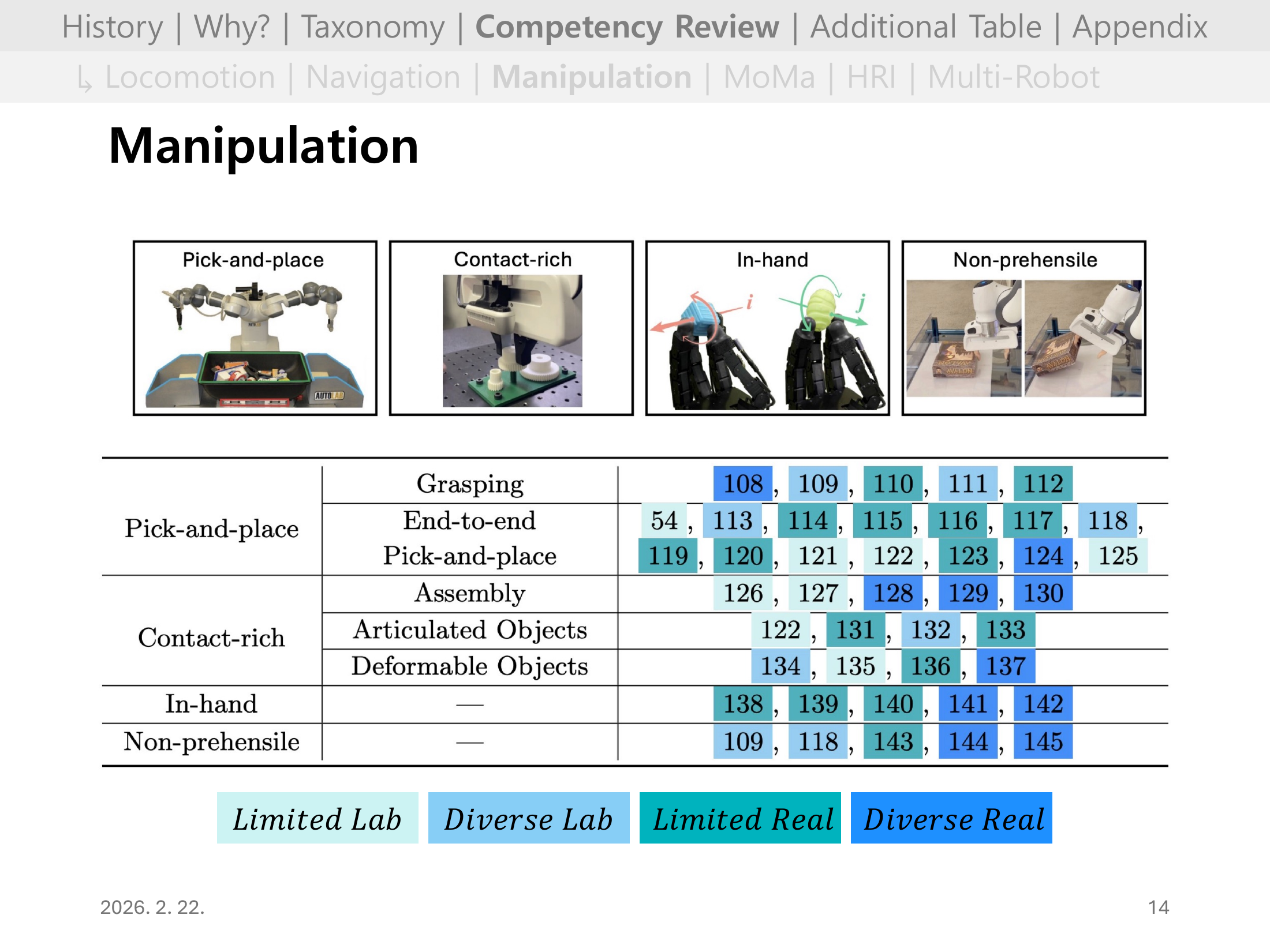
Slide 10. Manipulation 개요
조작은 상태/행동공간이 크고 접촉 동역학이 복잡해 학습 난이도가 높다.
그래도 과업을 제한하면 실세계 성과가 빠르게 올라간다는 점이 관찰된다.
Slide 11. Manipulation 핵심 요약

grasping, in-hand처럼 과업 정의가 명확한 경우 zero-shot sim-to-real이 잘 작동한다.
반대로 open-world pick-and-place는 다양성과 장기 의존성 때문에 멀티태스크/평생학습/자율 리셋 등 추가 기술이 필요하다.
Slide 12. Manipulation (cont.) 통합 과제
현재 연구는 조작 하위문제를 분리해 푸는 경향이 강하다.
앞으로는 충돌회피, 대칭성 priors, 다양한 액션공간을 한 시스템으로 통합하는 설계가 핵심 과제가 된다.
Slide 13. MoMa(Mobile Manipulation) 개요

MoMa는 이동과 조작을 동시에 요구하는 복합 문제다.
실험 설계 자체가 어려워 단일 조작 과제 대비 성공 사례가 적은 편이다.
Slide 14. MoMa 핵심 요약
초기 성공은 있었지만 주로 단기 과업 중심이며, 액션공간 선택이 성능에 큰 영향을 준다.
멀티태스크, 장기기억, 안전탐색이 MoMa 확장의 핵심 병목으로 제시된다.
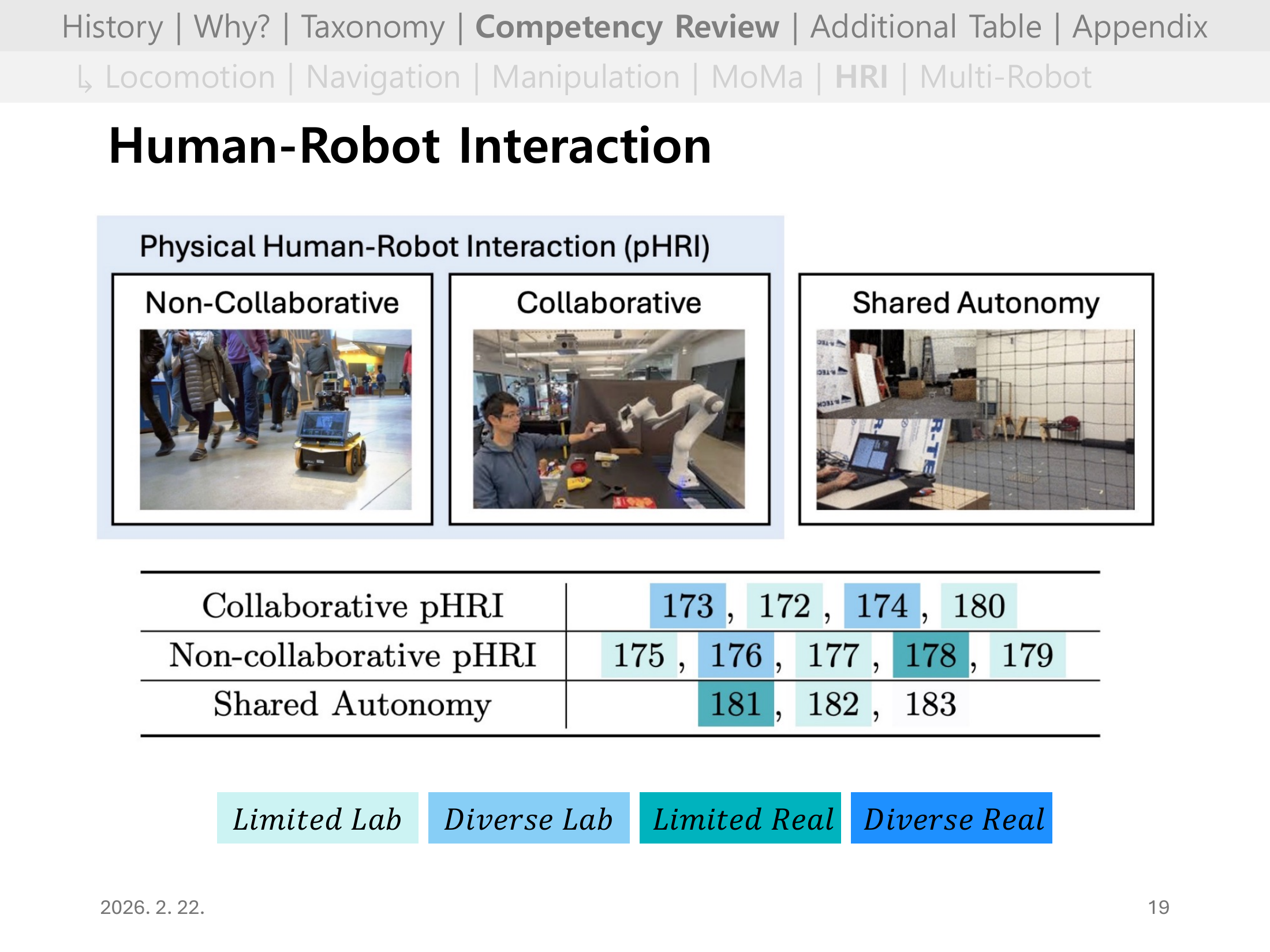
Slide 15. HRI 개요

HRI는 사람이 환경의 일부가 아니라 상호작용 주체라는 점에서 난이도가 급상승한다.
사람 데이터 수집 비용과 윤리/안전 문제 때문에 대규모 학습이 쉽지 않다.
Slide 16. HRI 핵심 요약

사람 행동은 비마코프성, 제한합리성 등으로 단순 모델링이 어렵다.
향후 방향은 사람과 함께하는 안전한 실세계 학습, 그리고 더 현실적인 인간행동 시뮬레이션 구축이다.
Slide 17. Multi-Robot 개요

다중로봇은 상호작용으로 인해 문제 복잡도가 급격히 증가한다.
개별 정책 최적화뿐 아니라 팀 단위 안정성과 확장성이 동시에 요구된다.
Slide 18. Multi-Robot 핵심 요약

동질적 협업 환경(예: 충돌회피)에서는 성공이 있으나, 일반적 비협조 환경은 아직 미성숙하다.
통신 설계, 학습 수렴성, 확장 가능한 협업 전략이 핵심 과제다.
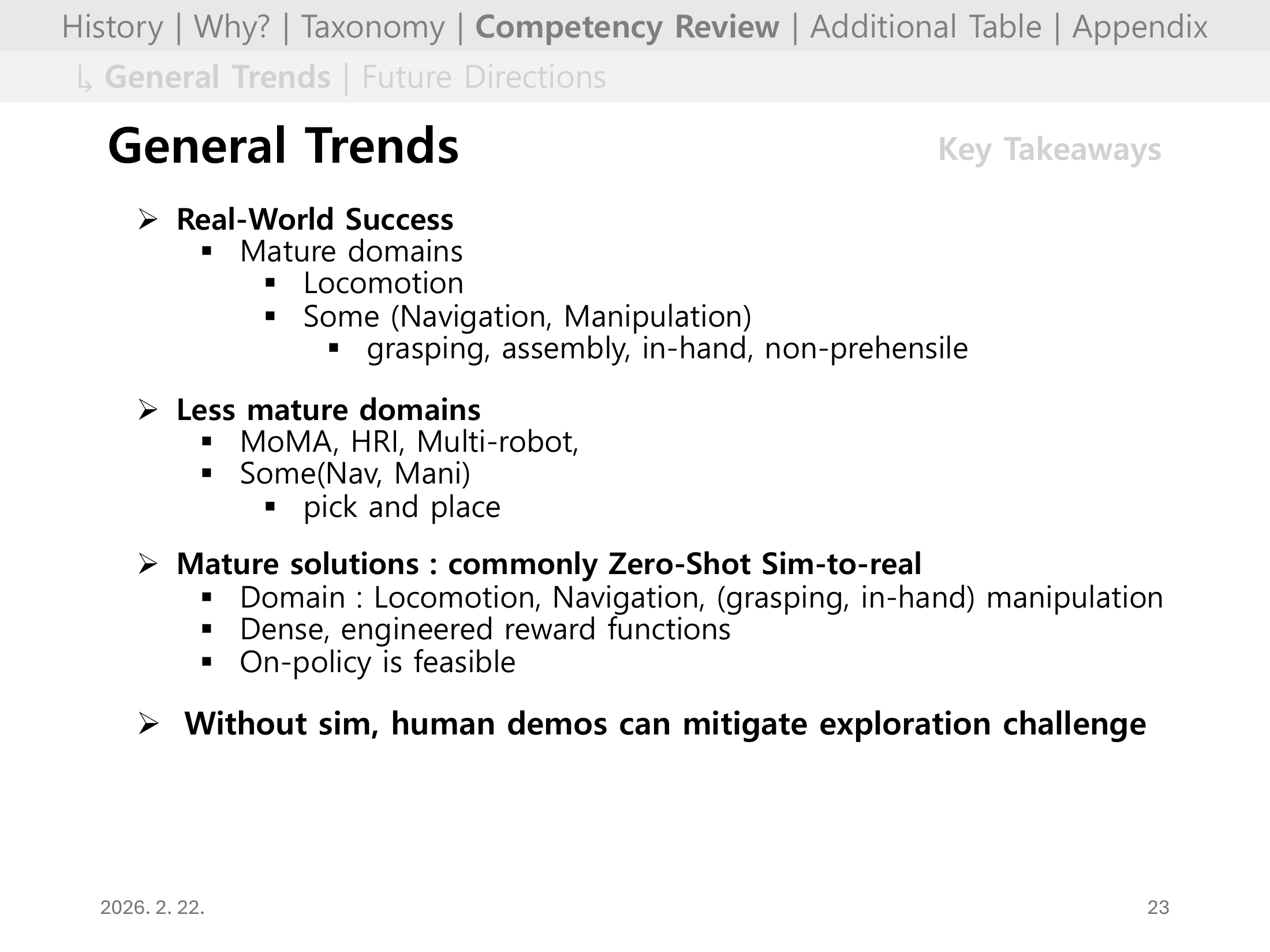
Slide 19. General Trends
성숙한 영역은 locomotion과 일부 navigation/manipulation이며, MoMa/HRI/multi-robot은 상대적으로 덜 성숙하다.
성공 사례 다수는 시뮬레이션 구축이 비교적 쉬운 문제에서의 sim-to-real + 치밀한 보상설계라는 공통점을 보인다.
Slide 20. Future Directions I

향후 1순위는 학습 안정성/샘플 효율 개선과 실세계 학습 가능성 확대다.
특히 장기 과업에서 “어떤 스킬을 학습해 어떻게 조합할지”가 시스템 설계의 핵심 질문으로 제시된다.
Slide 21. Future Directions II

보상설계, 액션공간, 고전 제어와의 결합을 원리적으로 다루는 접근이 필요하다.
또한 표준 벤치마크와 파운데이션 모델 활용(일반화, 언어조건, 데이터/시뮬 생성)이 중요한 확장 방향이다.
Slide 22. Multi-Robot Interaction 핵심 요약

동질적 협력 환경에서는 성과가 있지만, 복잡도와 확장성 문제가 여전히 크다는 점을 정리한다.
핵심 과제는 에이전트 간 통신, 학습 수렴성/안정성, 그리고 비협조 일반 상황으로의 확장이다.
Slide 23. General Trends
성숙한 영역(Locomotion, 일부 Navigation/Manipulation)과 미성숙 영역(MoMa, HRI, Multi-Robot)을 비교해 전체 지형을 보여준다.
또한 성숙한 해법의 공통점으로 zero-shot sim-to-real, dense reward engineering, on-policy 학습 가능성을 제시한다.
Slide 24. Key Future Directions

향후 연구 방향으로 보상/행동공간의 원리적 설계, 고전적 모델 기반 방법과의 통합, 표준 벤치마킹을 강조한다.
또한 파운데이션 모델을 활용한 일반화, 언어 조건화, 보상/시뮬 자산 생성 가능성을 확장 포인트로 제시한다.
Slide 25. Additional Table: Problem Formulation (Table 1)
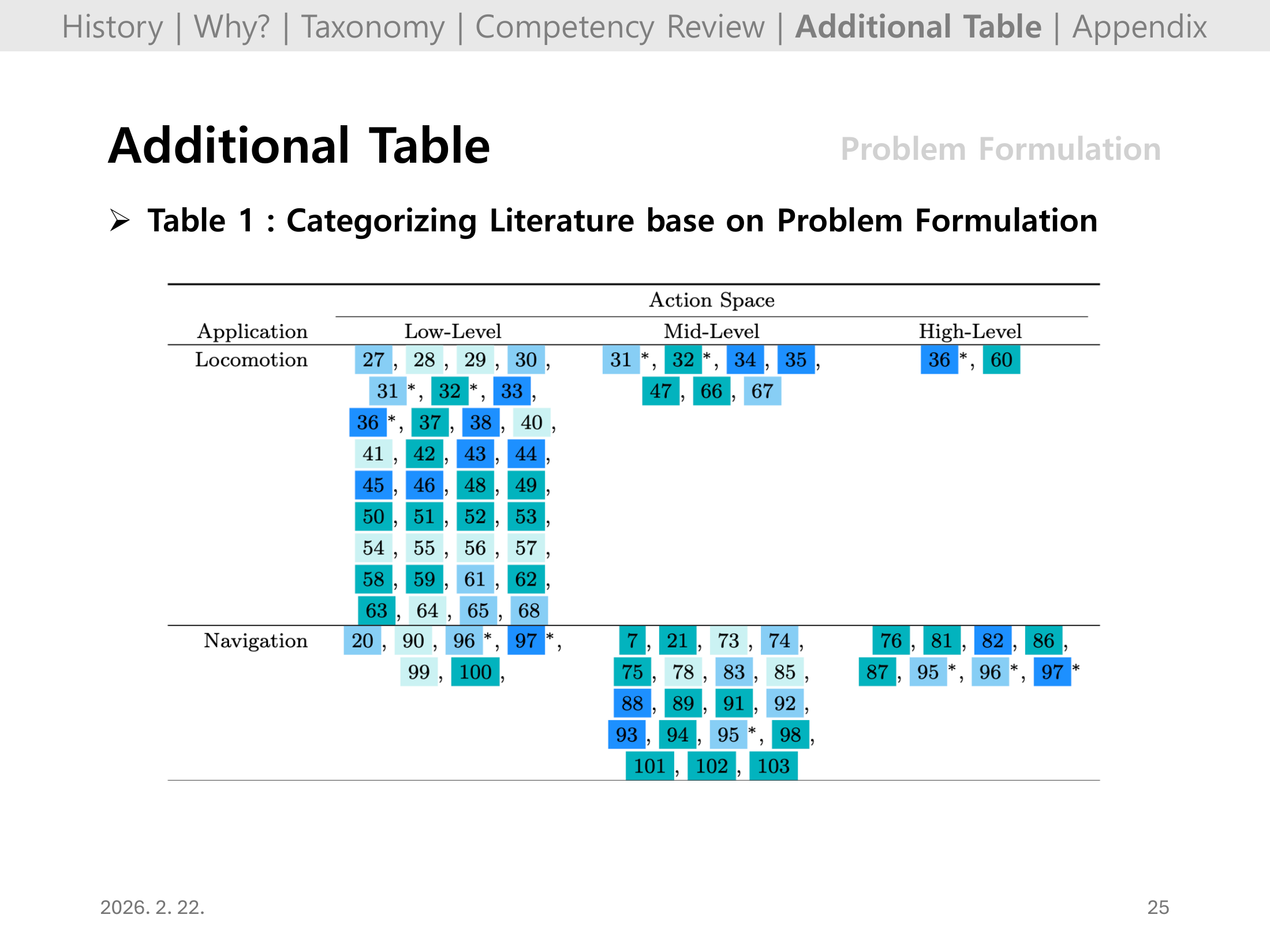
이 장은 논문의 Table 1을 통해 문제 공식화 축(action/observation/reward)을 기준으로 기존 문헌을 체계적으로 정렬한다.
즉, 어떤 과제에서 어떤 문제 정의가 많이 쓰였는지 한눈에 비교할 수 있는 참고 표다.
Slide 26. Additional Table: Problem Formulation (Table 1, continued)
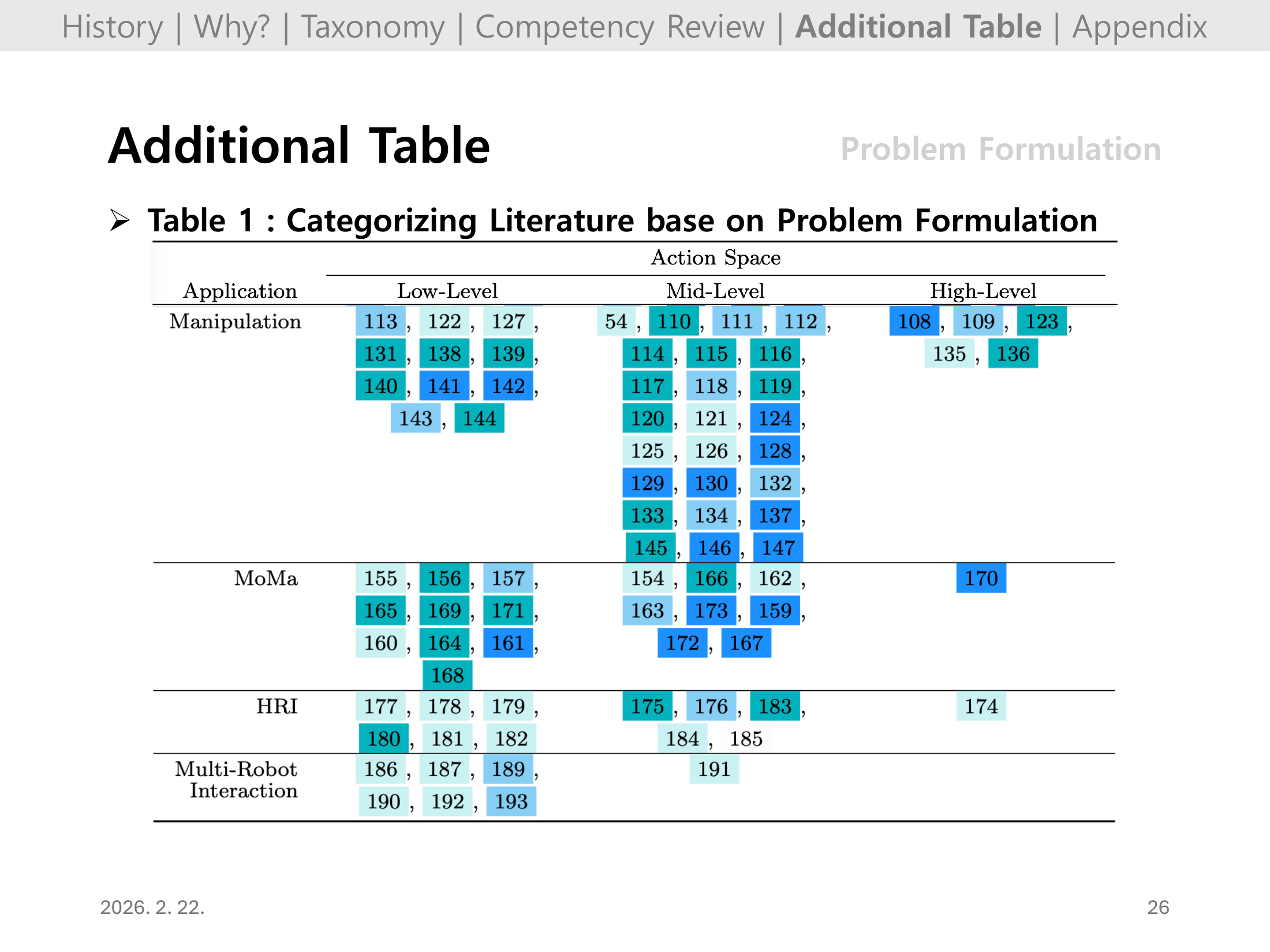
Slide 25의 연속 페이지로, 동일한 분류 기준을 더 많은 문헌에 확장해 보여준다.
발표 시에는 내 관심 과제와 유사한 문제 설정(보상/관측/행동공간)을 찾아 근거로 인용하기 좋다.
Slide 27. Additional Table: Problem Formulation (Table 2)

Table 2에서는 다른 관점의 문제 공식화 분류를 보강해, domain 간 공통 패턴과 차이를 비교하게 해준다.
특히 어느 도메인이 sparse/dense reward에 의존하는지, 관측 차원이 어떻게 달라지는지 확인하는 용도로 유용하다.
Slide 28. Additional Table: Problem Formulation (Table 2, continued)
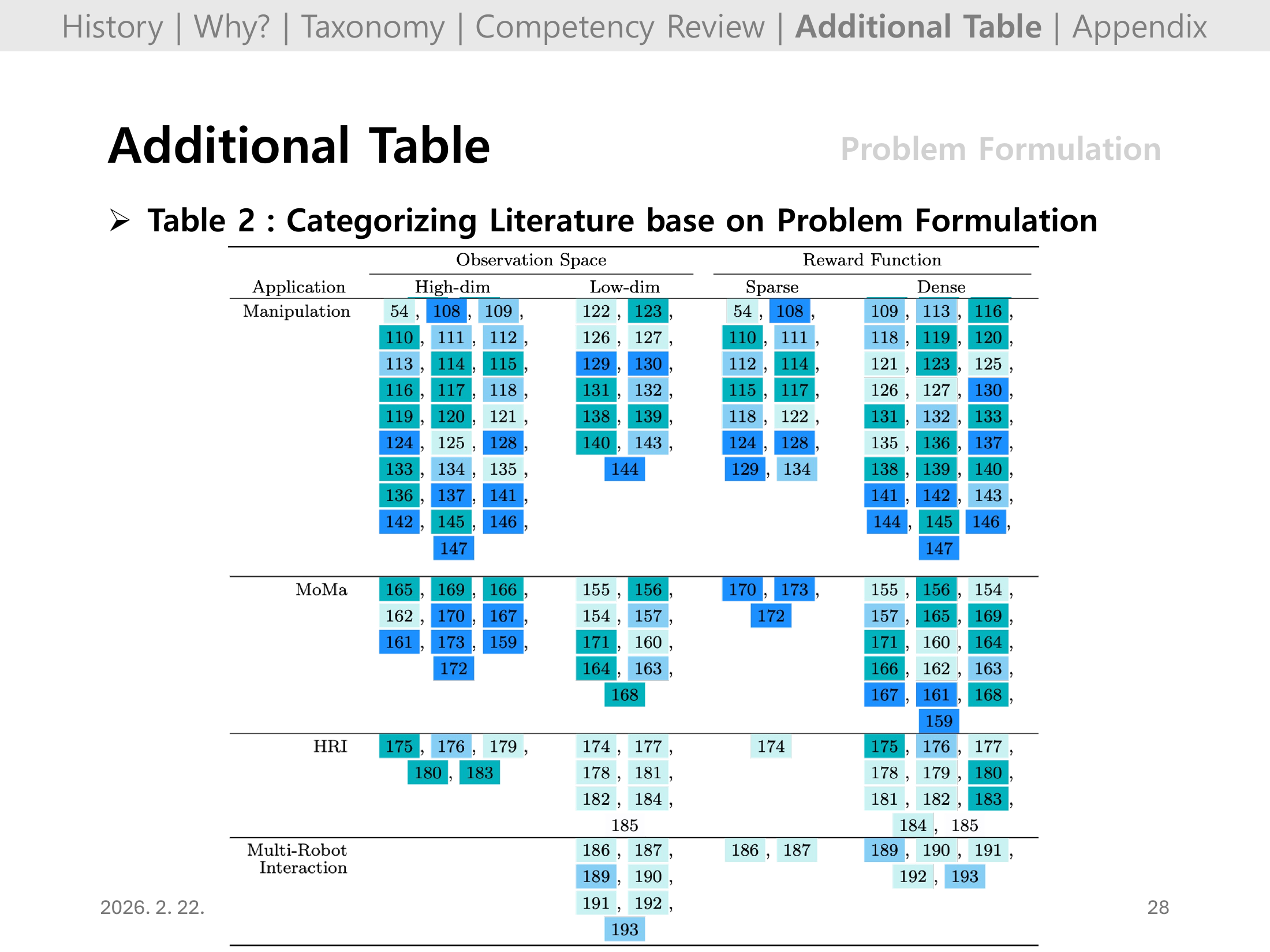
Slide 27의 연장으로, 표 기반 근거를 충분히 제시해 발표 결론의 신뢰도를 높이는 페이지다.
요약할 때는 “내가 선택한 태스크가 왜 해당 문제설정을 택해야 하는지”를 이 표와 연결하면 좋다.
Slide 29. Additional Table: Solution Approach (Table 3)

Table 3는 solution approach(예: sim-to-real, model-free/model-based, policy optimization) 관점에서 문헌을 분류한다.
성공 사례가 어떤 학습 파이프라인 조합에서 주로 나왔는지 근거를 제시하는 핵심 부록 표다.
Slide 30. Additional Table: Solution Approach (Table 3, continued)
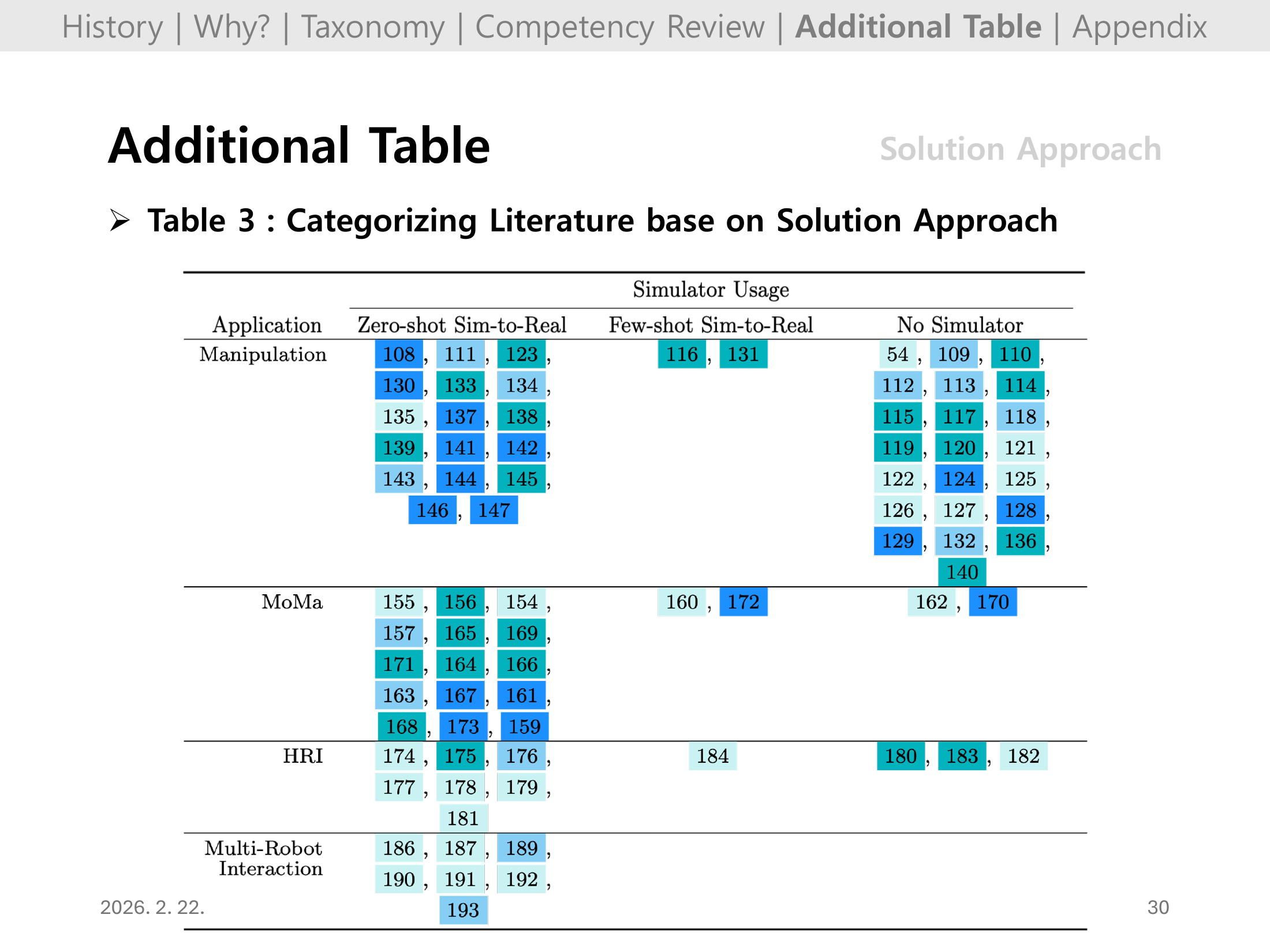
마지막 장은 solution approach 표의 연속으로, 리뷰 전체의 “방법론별 지형도”를 마무리한다.
내 결론에서는 이 표를 근거로, 다음 프로젝트에서 채택할 학습 전략(예: zero-shot sim-to-real vs real-world finetuning)을 명확히 제안하면 좋다.
5) 내 결론 (초안)
- DRL의 실제 성공은 이미 존재하지만, 문제 유형에 따라 성숙도 편차가 매우 크다.
- 지금까지의 성공 공통점은 sim-to-real 가능 문제 + 정교한 엔지니어링(보상/도메인랜덤화/액션설계)이다.
- 앞으로의 승부처는 실세계 학습 안정화, 장기과업 통합, 사람/다중에이전트 상호작용 일반화다.
6) 원문/발표/연구 기관 링크
- 논문(arXiv HTML): https://arxiv.org/html/2408.03539
- 논문(PDF): https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/chen_tang_ARCRAS2024.pdf
- 원래 발표 슬라이드(PDF): https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/chen_tang_ARCRAS2024.slides.pdf
- Learning Agents Research Group (LARG): https://www.cs.utexas.edu/~pstone/research.shtml
- Texas Robotics: https://robotics.utexas.edu
- RoBin Lab: https://robin-lab.cs.utexas.edu