#논문 리뷰
Deep Reinforcement Learning for Robotics, A Survey of Real-World Successes
수업 과제에서 논문 리뷰 관심 있는 것이 있어서, 가지고 오게 되었다.
#1) 논문 한눈에 보기
- 논문: Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes
- 버전: arXiv v3 (2024-09-16)
- 핵심 질문:
- DRL이 실제 로봇 문제에서 어디까지 성공했는가?
- 어떤 영역은 성숙했고, 어떤 영역은 아직 어려운가?
이 논문은 단순 알고리즘 비교가 아니라, 실제 로봇 환경에서의 성과를 기준으로 DRL 연구를 분류하고 성숙도를 평가한다.
#2) 논문 핵심 프레임워크
논문은 DRL 로보틱스 연구를 아래 4축으로 분석한다.
| 분석 축 | 설명 |
|---|---|
| Robotic Competency | 로봇이 학습한 능력(이동, 조작, 사람/다중로봇 상호작용) |
| Problem Formulation | 상태/관측/보상/행동공간을 어떻게 RL 문제로 정의했는지 |
| Solution Method | 시뮬레이션 기반, sim-to-real, real-world learning 등 학습 전략 |
| Level of Real-World Success | 실험 성과를 실제 적용 성숙도(레벨)로 평가 |
#Real-World Success 레벨 (요약)
| 레벨 | 의미 |
|---|---|
| L0 | 시뮬레이션에서만 검증 |
| L1 | 제한된 실험실 환경 검증 |
| L2 | 다양한 실험실 환경 검증 |
| L3 | 제한된 실제 환경 검증 |
| L4 | 다양한 실제 환경 검증 |
| L5 | 상용 제품/서비스 수준 배포 |
#3) 발표 슬라이드 업로드 방식
아래처럼 슬라이드 이미지를 올린 뒤, 각 장 설명을 채워 넣는다.
- 이미지 경로 예시:
/assets/slides/drl-robot-251110/slide-01.png - 파일명 규칙:
slide-01.png,slide-02.png, …,slide-30.png - 한 슬라이드당 구성:
- 슬라이드 이미지 1개
- 핵심 메시지 2~4문장
- 내 해석/비판 2~3문장
#4) 슬라이드별 설명 초안 (30장)
#Slide 01. 제목/저자 소개

이 발표는 DRL이 실제 로보틱스에 얼마나 성공적으로 적용되었는지 체계적으로 정리한 서베이를 소개한다.
저자진은 UT Austin, University of Virginia, Sony AI 소속으로 구성되어 있고, 발표 범위가 넓어 이후 슬라이드의 분류 체계가 중요하다.
#Slide 02. 목차 및 버전 이력
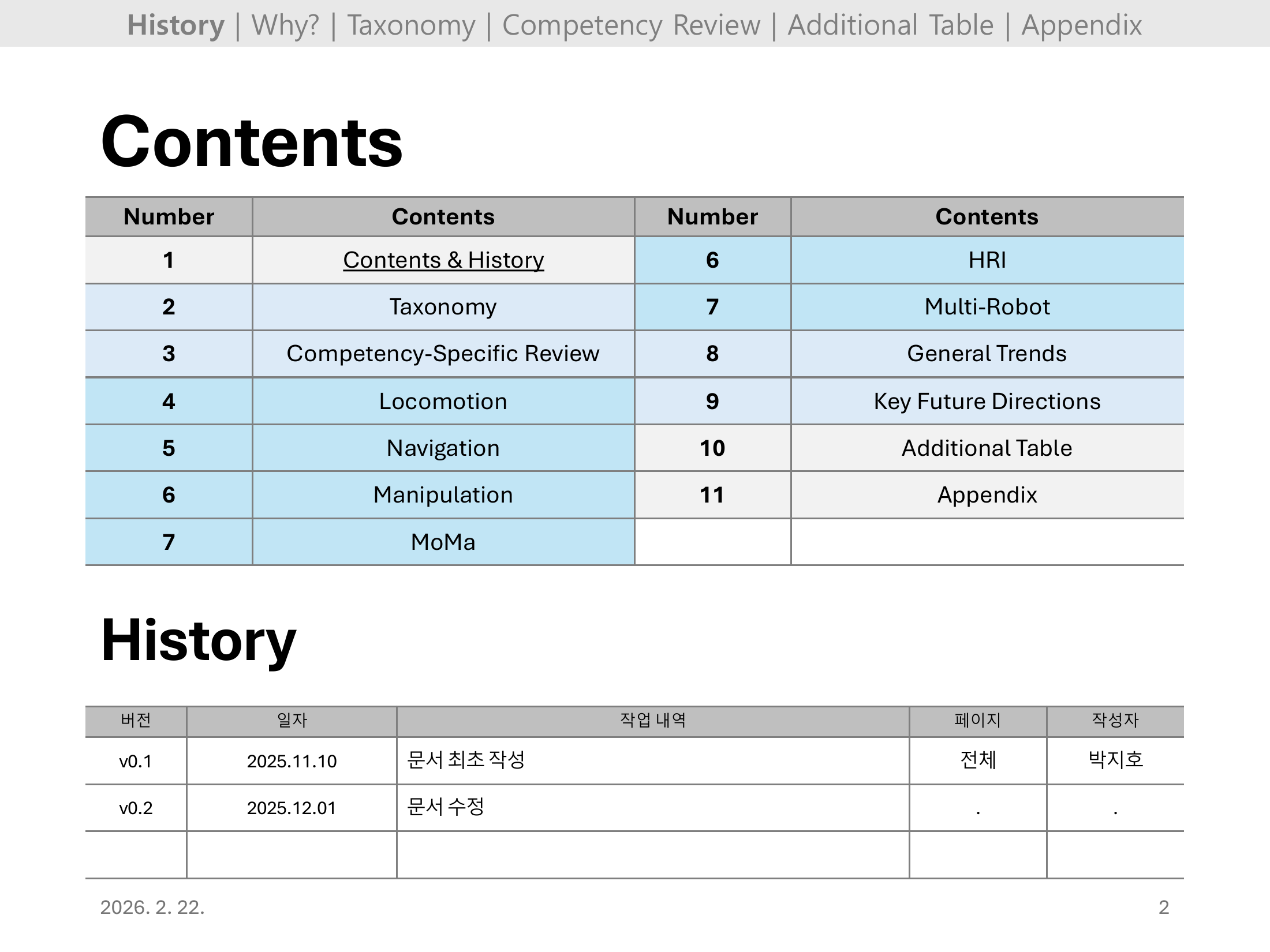
발표 구성은 총 13개 섹션(Contents&History → Taxonomy → Competency Review → Locomotion → Navigation → Manipulation → MoMa → HRI → Multi-Robot → General Trends → Key Future Directions → Additional Table → Appendix)으로 이루어진다.
버전 이력(v0.1: 2025.11.10 최초 작성, v0.2: 2025.12.01 수정)도 포함되어 있어 발표 준비 과정을 확인할 수 있다.
#Slide 03. 이 서베이의 필요성 (Why This Survey)

기존 서베이는 시뮬레이션 중심이거나 특정 기술·작업에 편향되어 있었다. 이 논문은 ① 실세계 성공 중심 분석, ② 새로운 DRL 분류 체계(역량/문제식형태/Solution/Success Level), ③ 최신 DRL 발전 배경(시뮬 → 실세계 전환) 세 가지 이유로 기획됐다.
즉, “어디서 성공했는가?”라는 질문에 체계적으로 답하기 위한 틀이 이 서베이의 존재 이유다.
#Slide 04. 분류: 로봇 능력 체계 (Robot Competencies)
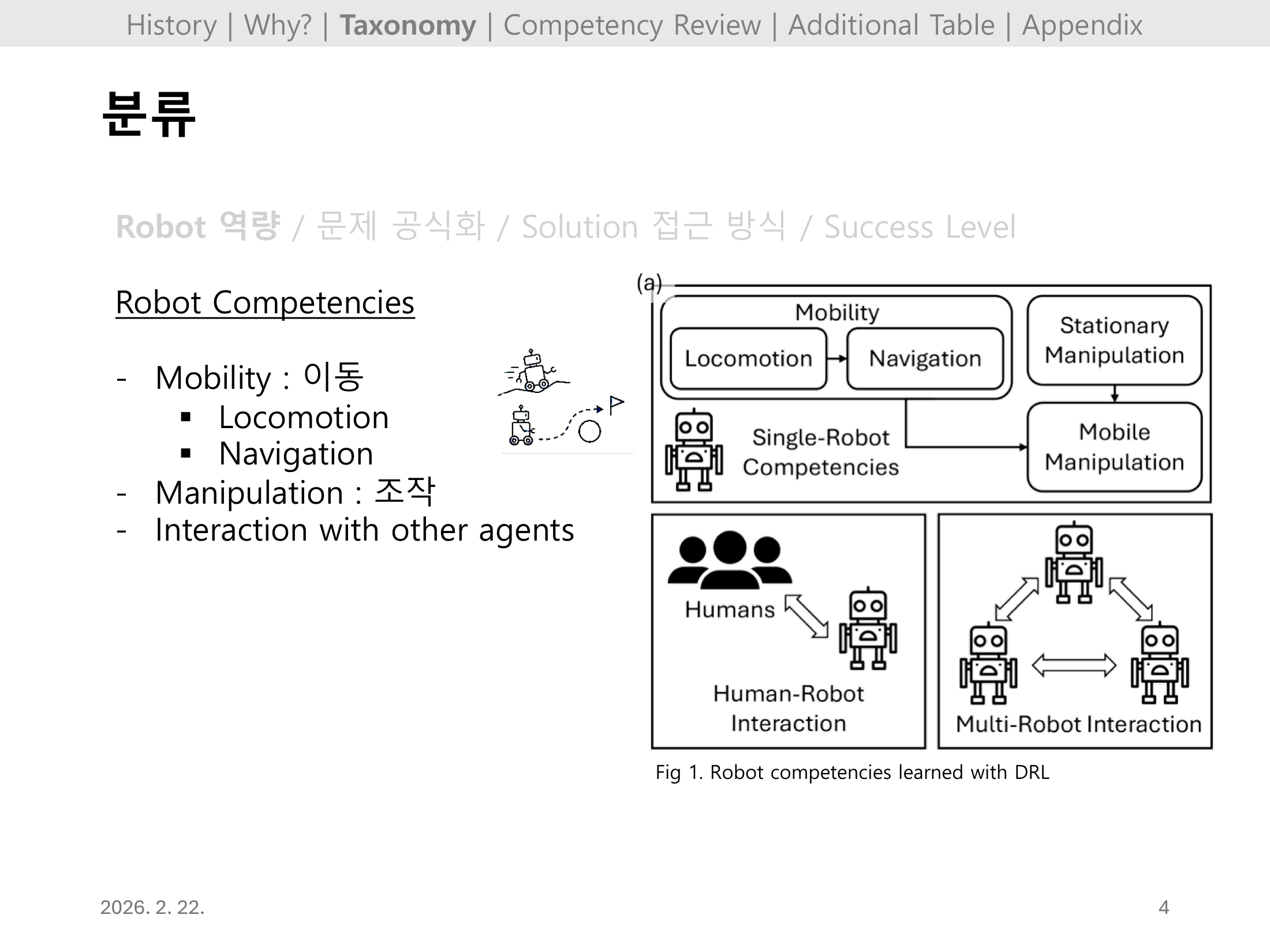
DRL로 학습 가능한 역량을 Mobility(Locomotion + Navigation), Manipulation(조작), Interaction with other agents(HRI + Multi-Robot)로 계층화한다.
Fig 1 다이어그램은 Single-Robot Competencies가 어떻게 Mobile Manipulation으로 연결되고, 나아가 인간·다중로봇 상호작용으로 확장되는지를 한눈에 보여준다.
#Slide 05. 분류: 문제 공식화 (Problem Formulation)
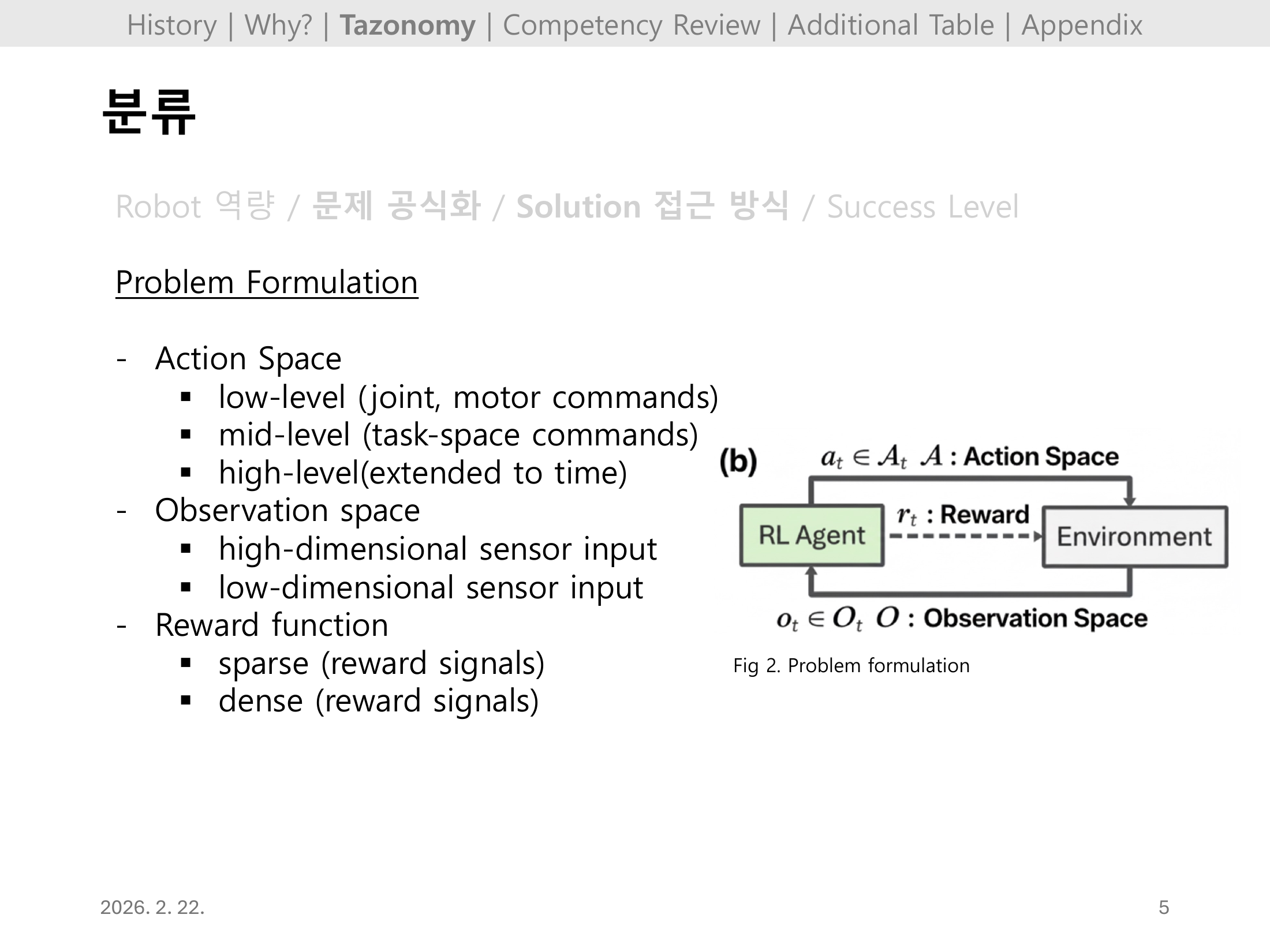
RL 문제 정의는 Action Space(low-level 관절 명령 / mid-level 태스크 공간 / high-level 시간 확장), Observation Space(고차원 센서 입력 vs 저차원 센서 입력), Reward Function(sparse vs dense) 세 축으로 분류한다.
Fig 2의 표준 MDP 다이어그램(Agent ↔ Environment: 액션·보상·관측)은 이 분류가 실제 어떻게 적용되는지를 직관적으로 정리한다.
#Slide 06. 분류: 해법 접근 방식 1 (Solution Approach)
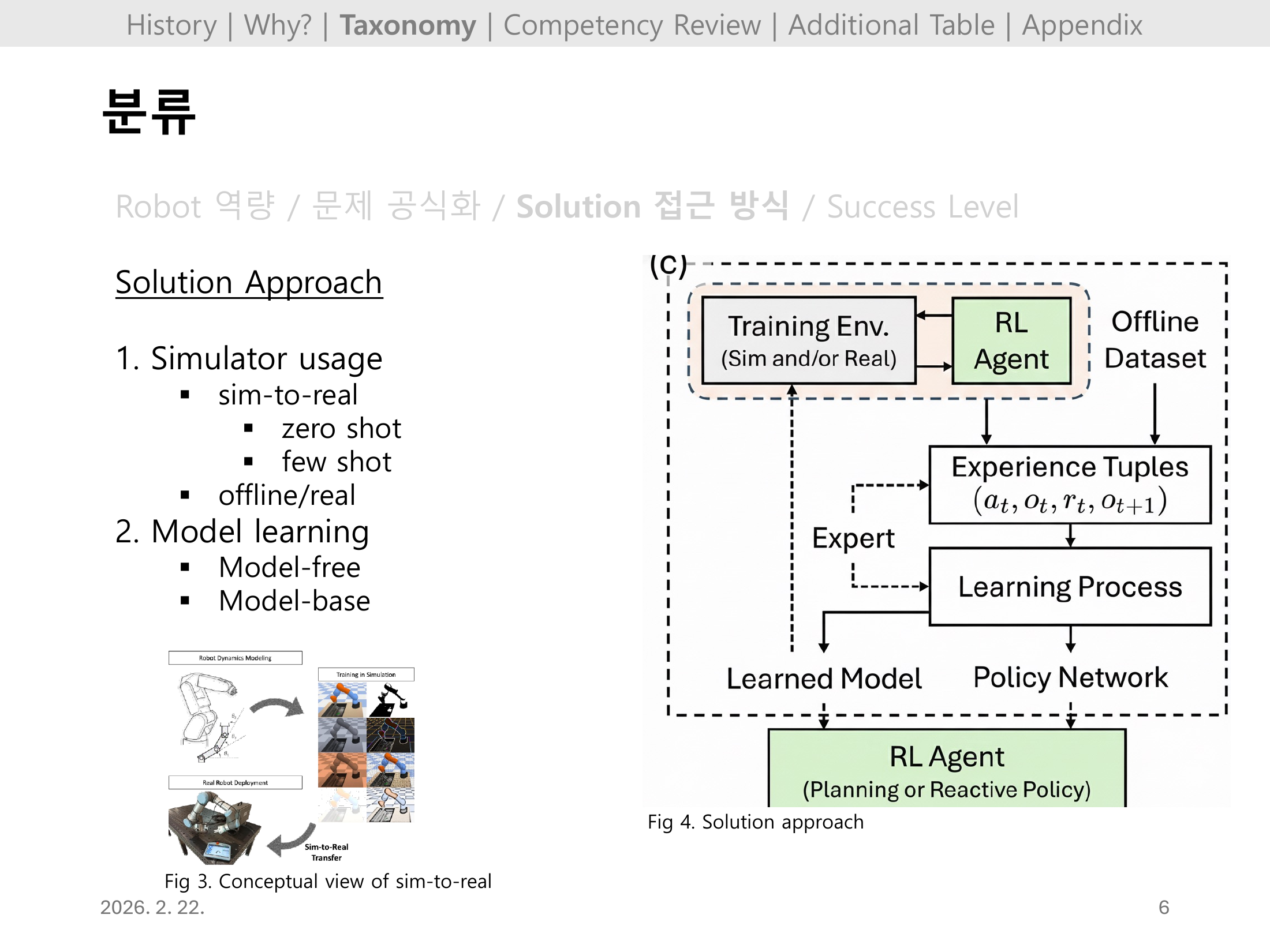
Simulator usage 측면에서 sim-to-real(zero-shot, few-shot), offline/real 학습으로 구분되며, Model learning은 Model-free와 Model-based로 나뉜다.
Fig 3(sim-to-real 개념도)과 Fig 4(전체 파이프라인: Training Env → Experience Tuples → Learning Process → Policy Network → RL Agent)가 함께 제시되어 Solution Approach 체계의 기반을 시각화한다.
#Slide 07. 분류: 해법 접근 방식 2 (Solution Approach, cont.)
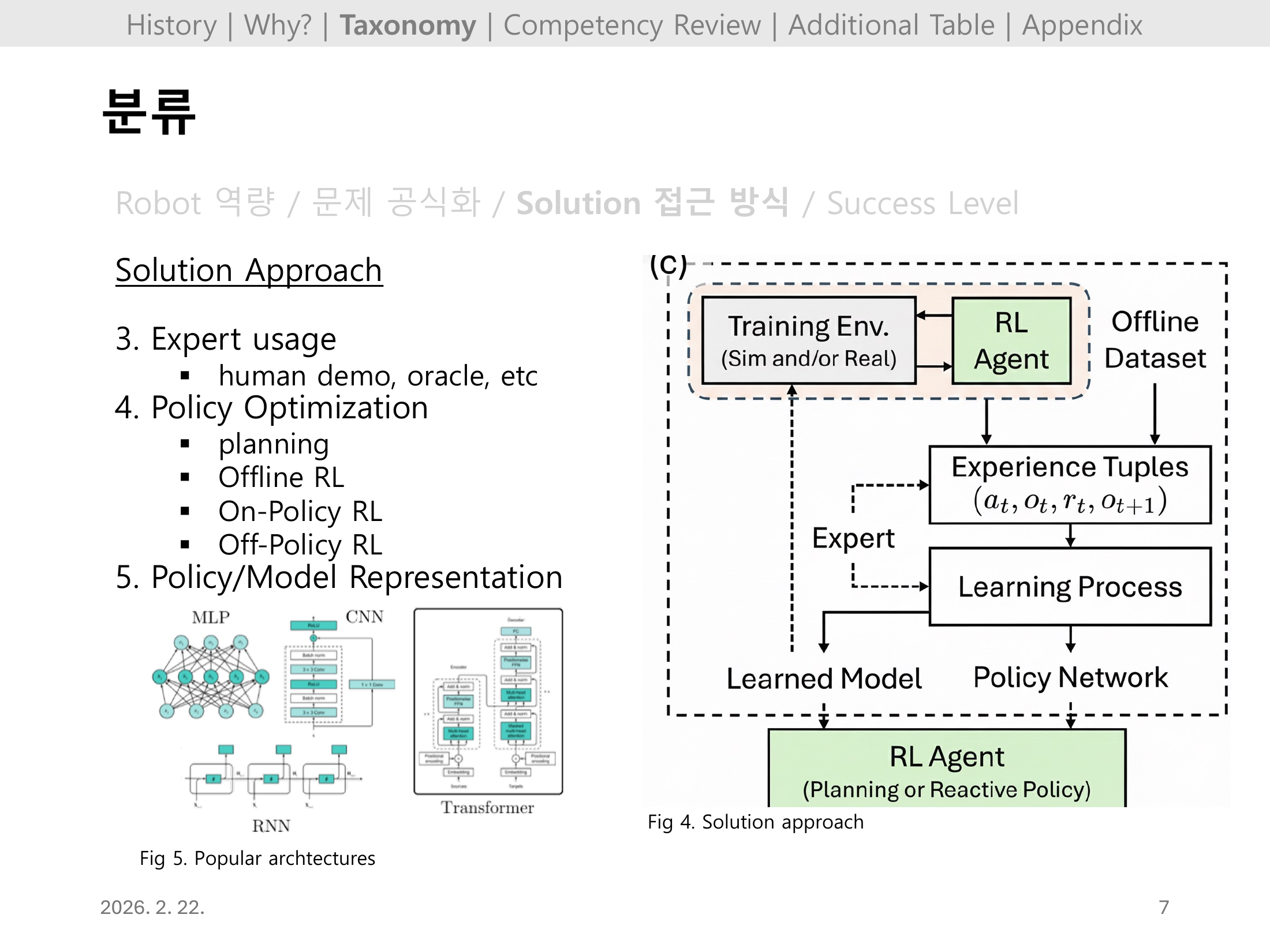
Expert usage(human demo, oracle 등), Policy Optimization(planning, Offline/On-Policy/Off-Policy RL), Policy·Model Representation(MLP, CNN, RNN, Transformer) 세 범주로 Solution Approach가 완성된다.
이 구분 체계는 이후 각 역량 섹션에서 어떤 방법 조합이 실세계 성공으로 이어졌는지 비교하는 기준이 된다.
#Slide 08. 분류: 실세계 성공 레벨 (Real-World Success Level)

기술성숙도(Technology Readiness Level)에서 영감을 받아 Level 0(시뮬레이션에서만 검증)~Level 5(상용 제품·서비스 배포)를 정의한다.
같은 RL 알고리즘이라도 어느 환경에서 검증됐는지에 따라 의미가 크게 다르므로, 이 레벨 체계는 문헌 비교의 핵심 기준이 된다.
#Slide 09. Competency-Specific Review 소개 및 색상 범례

이후 섹션은 Locomotion, Navigation, Manipulation, MoMa, HRI, Multi-Robot 각 역량을 집중 리뷰하며, 논문 레퍼런스를 성숙도 기준으로 색상 코딩해 제시한다.
색상 범례: Limited Lab(연한 파랑) / Diverse Lab(파랑) / Limited Real(청록) / Diverse Real(진한 청록) — 이 기준으로 이후 모든 표를 해석하면 된다.
#Slide 10. Locomotion 개요
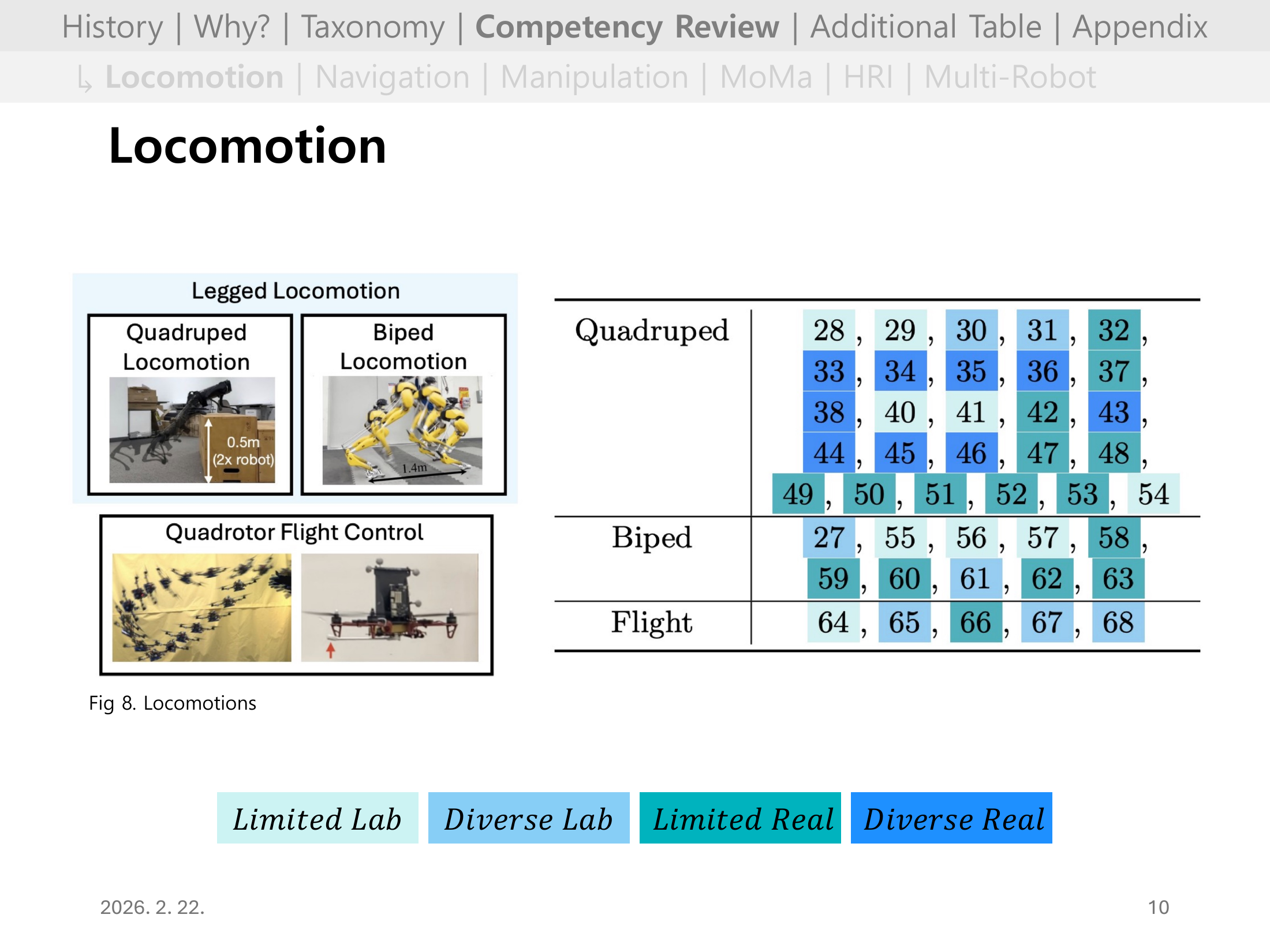
Legged Locomotion(Quadruped, Biped)과 Quadrotor Flight Control로 분류된 문헌들을 레퍼런스 번호 + 성숙도 색상으로 정리한 표다.
Quadruped는 Diverse Real까지 색이 넓게 퍼져 있어 성숙도가 가장 높고, Biped와 Flight는 상대적으로 Limited 영역에 집중되어 있다.
#Slide 11. Locomotion 핵심 요약

DRL 기반 사족보행(quadruped) 구현은 성숙도 높음; 이족보행은 DoF가 높고 동역학이 어려워 덜 성숙하다. 핵심 성공 패턴은 Zero-shot Sim-to-real(On-policy Model-Free)과 Privileged information(특권 정보 가진 Teacher → Student 증류).
Open questions: 효율적·안전한 real-world 학습, 이동과 다른 작업(고차원·복합·장기 목표)의 통합 방법.
#Slide 12. Navigation 개요
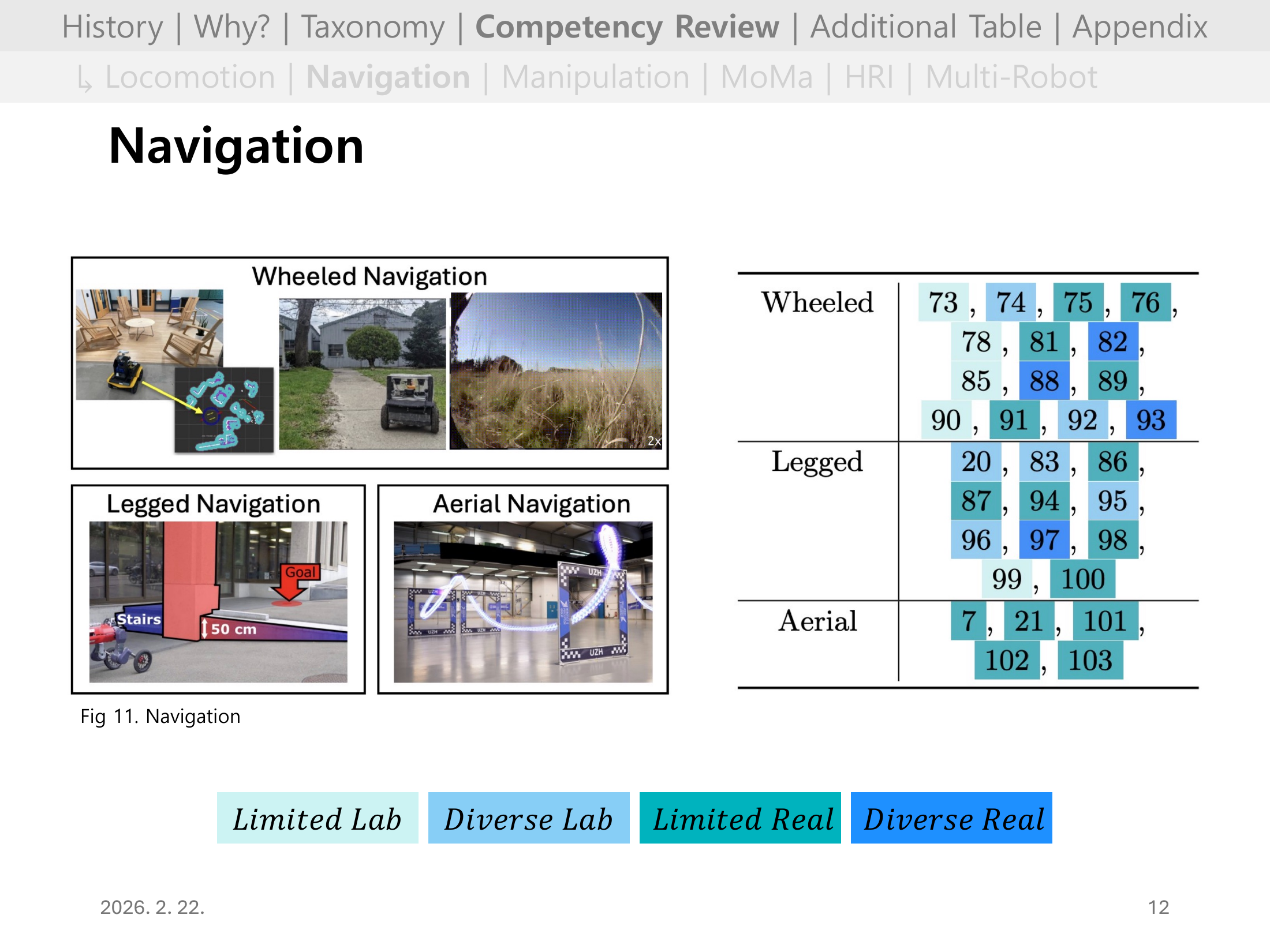
Wheeled, Legged, Aerial 플랫폼별로 문헌을 레퍼런스 번호 + 성숙도 색상으로 정리한 표다.
Wheeled Navigation은 Diverse Lab/Real 사례가 많고, Aerial은 상대적으로 Diverse Real 사례가 적어 성숙도 차이가 뚜렷하다.
#Slide 13. Navigation 핵심 요약

실내 Nav에서 end-to-end RL이 시뮬레이션 상 뛰어나지만, real-world에서는 모듈식(classical stacks)이 가장 성공적이다. 일반화·설명 가능성·안전성이 부재하며, local plan + semantic exploration이 유망한 접근이다.
Open questions: Nav stacks 중 얼마나 학습으로 대체할지, Nav와 Locomotion을 어떻게 함께 학습할지, Safety Critical 분야(자율주행 등)에서의 RL 역할.
#Slide 14. Manipulation 개요
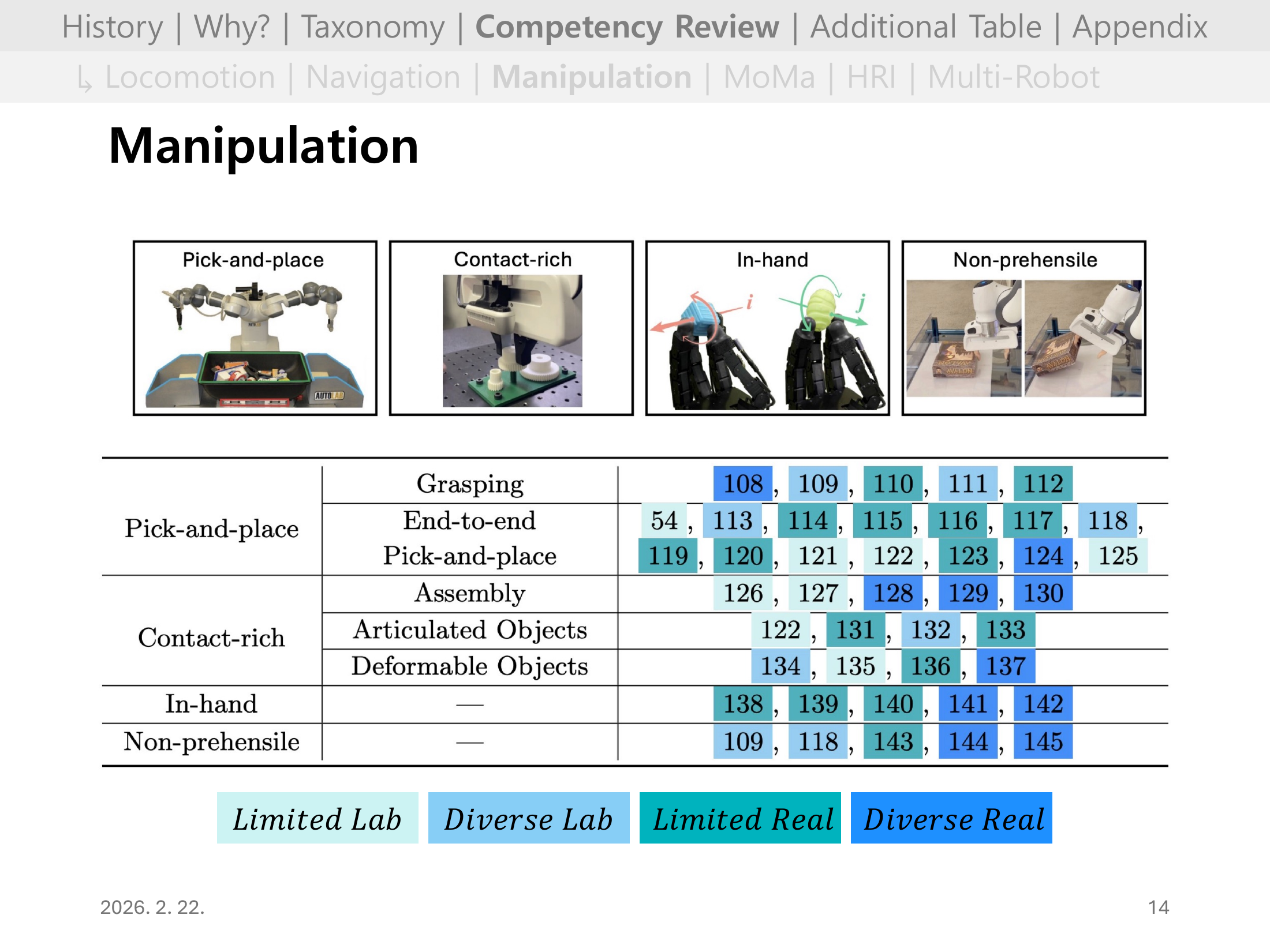
조작 문헌을 Pick-and-place(Grasping / End-to-end / Pick-and-place), Contact-rich(Assembly / Articulated Objects / Deformable Objects), In-hand, Non-prehensile로 세분화해 레퍼런스 번호 + 성숙도로 정리했다.
사진 예시(pick-and-place, contact-rich, in-hand, non-prehensile)로 각 서브태스크가 어떤 물리적 상호작용인지 한눈에 확인할 수 있다.
#Slide 15. Manipulation 핵심 요약

RL은 과제가 Constrained(물체·환경이 정해짐) + Enumerable a priori(목표·초기조건을 사전 열거 가능)할 때 가장 성공적 — grasping, in-hand manipulation이 대표 예.
Open-world 확장을 위해서는 Multi-task/Meta/Lifelong learning, Autonomous real-world learning(reward/reset 자동화), Learning from human video, Leveraging demonstrations가 필요하다.
#Slide 16. Manipulation 미결 과제 (Open Questions)

효과적인 priors(Symmetry, Collision-avoidance)를 어떻게 통합할지, 그리고 대부분 연구가 하나의 고립된 서브태스크(specific action space)만 다루는 현실에서 어떻게 통합된 시스템을 설계할지가 핵심 질문이다.
조작의 미래는 결국 “여러 서브 능력을 하나로 묶는 통합 설계”에 달려 있으며, 이 점이 Manipulation을 여전히 어렵게 만드는 주된 이유다.
#Slide 17. Mobile Manipulation (MoMa) 개요

MoMa 문헌을 WBC(Whole-Body Control), Short-Horizon Interactive Tasks, Long-Horizon Interactive Tasks로 분류하고 레퍼런스 + 성숙도를 정리했다.
Long-Horizon 과제는 대부분 Limited Lab 수준에 머물러, 이동과 조작을 동시에 장기적으로 다루는 것이 얼마나 어려운지를 잘 보여준다.
#Slide 18. Mobile Manipulation 핵심 요약

단기 과업에서는 sim-to-real 초기 성공 사례가 있으나, Action space 선택이 성능에 결정적 영향을 미치고, 다양한 형태(morphology)로의 확장도 중요하다.
Open questions: Multi-tasking, Long-term memory, Safe exploration — 이 세 가지가 MoMa의 실세계 확장을 막는 핵심 병목이다.
#Slide 19. Human-Robot Interaction (HRI) 개요
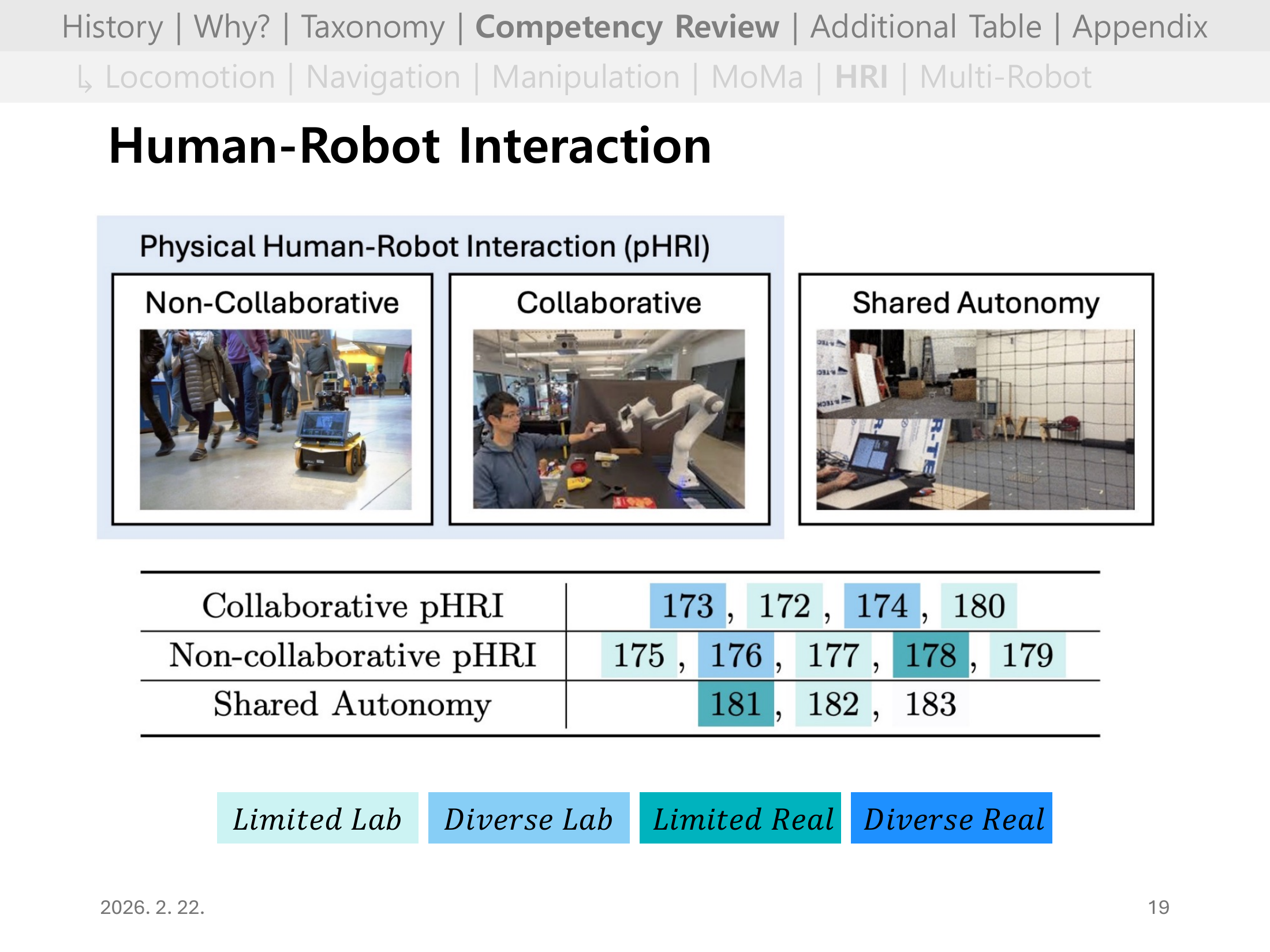
Physical HRI(pHRI)를 Non-Collaborative(혼잡한 공간에서의 회피), Collaborative(협동 작업), Shared Autonomy로 구분하고, 각 유형별 레퍼런스와 성숙도를 표로 정리했다.
HRI 전반의 성숙도는 Diverse Lab 이상이 드물어, 사람과의 상호작용이 포함될 때 RL 검증의 난이도가 얼마나 오르는지를 보여준다.
#Slide 20. Human-Robot Interaction 핵심 요약

단일 로봇 역량 대비 성공 사례가 적고, 인간 데이터 수집 자체가 어렵다(Non-Markovian, Limited rationality, 비용 高).
Future directions: 사람과 함께하는 안전한 real-world 학습 가능화, 더 현실적인 인간 행동 시뮬레이션 개발 — 이 두 방향이 해결되지 않으면 HRI DRL의 확장은 계속 막힌다.
#Slide 21. Multi-Robot Interaction 개요

Multi-Robot Collision Avoidance, Loco-Manipulation, Robot Soccer 세 유형의 사진과 레퍼런스 번호·성숙도를 정리했다.
Robot Soccer(참조 191)가 Diverse Real에 해당하고, Collision Avoidance도 일부 Diverse Real 사례가 있으나 전반적으로 성숙도가 낮다.
#Slide 22. Multi-Robot Interaction 핵심 요약

동질적 협력 환경에서는 성과가 있지만, 복잡도와 확장성 문제가 여전히 크다는 점을 정리한다.
핵심 과제는 에이전트 간 통신, 학습 수렴성/안정성, 그리고 비협조 일반 상황으로의 확장이다.
#Slide 23. General Trends
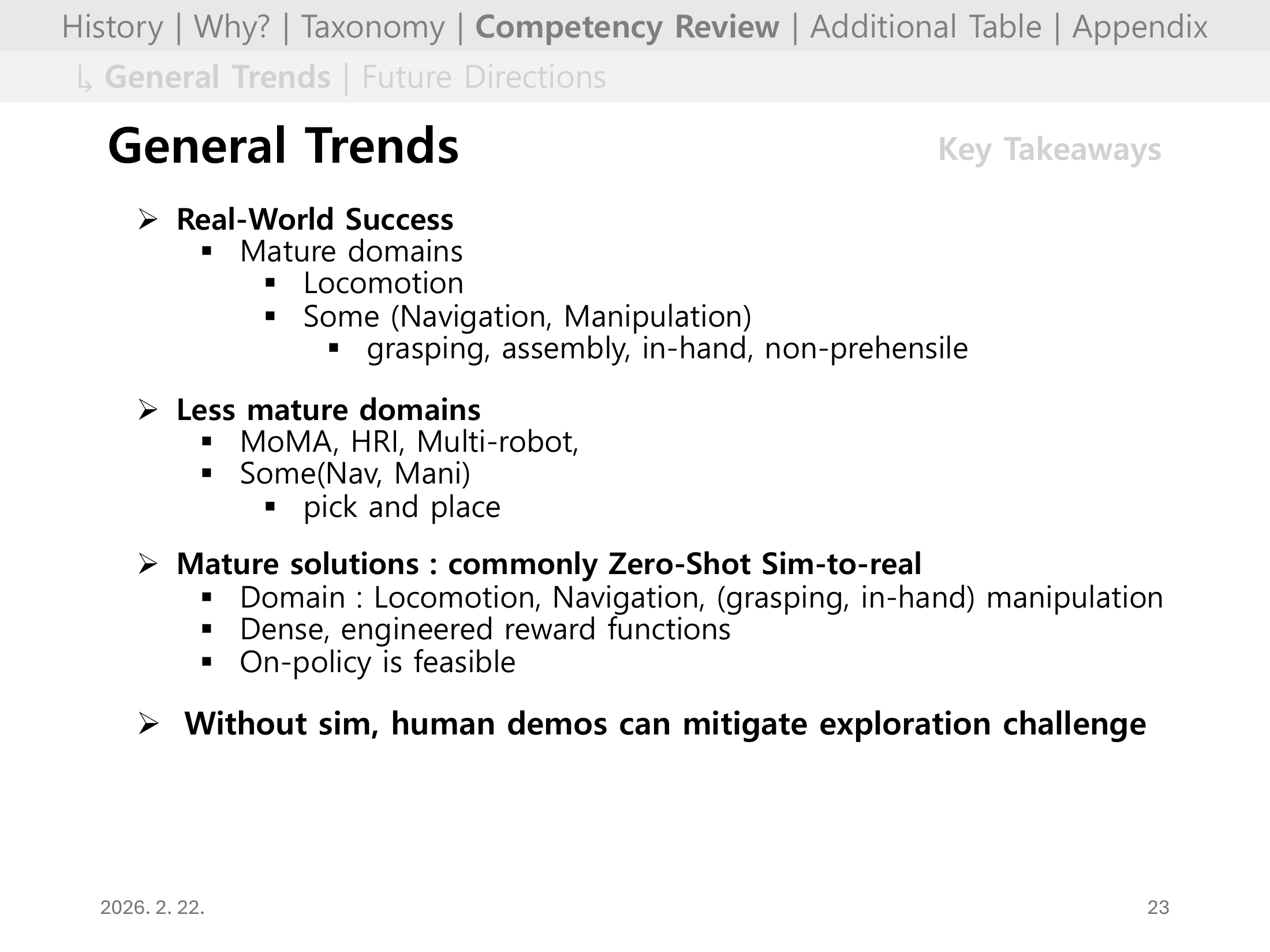
성숙한 영역(Locomotion, 일부 Navigation/Manipulation)과 미성숙 영역(MoMa, HRI, Multi-Robot)을 비교해 전체 지형을 보여준다.
또한 성숙한 해법의 공통점으로 zero-shot sim-to-real, dense reward engineering, on-policy 학습 가능성을 제시한다.
#Slide 24. Key Future Directions

향후 연구 방향으로 보상/행동공간의 원리적 설계, 고전적 모델 기반 방법과의 통합, 표준 벤치마킹을 강조한다.
또한 파운데이션 모델을 활용한 일반화, 언어 조건화, 보상/시뮬 자산 생성 가능성을 확장 포인트로 제시한다.
#Slide 25. Additional Table: Problem Formulation (Table 1)
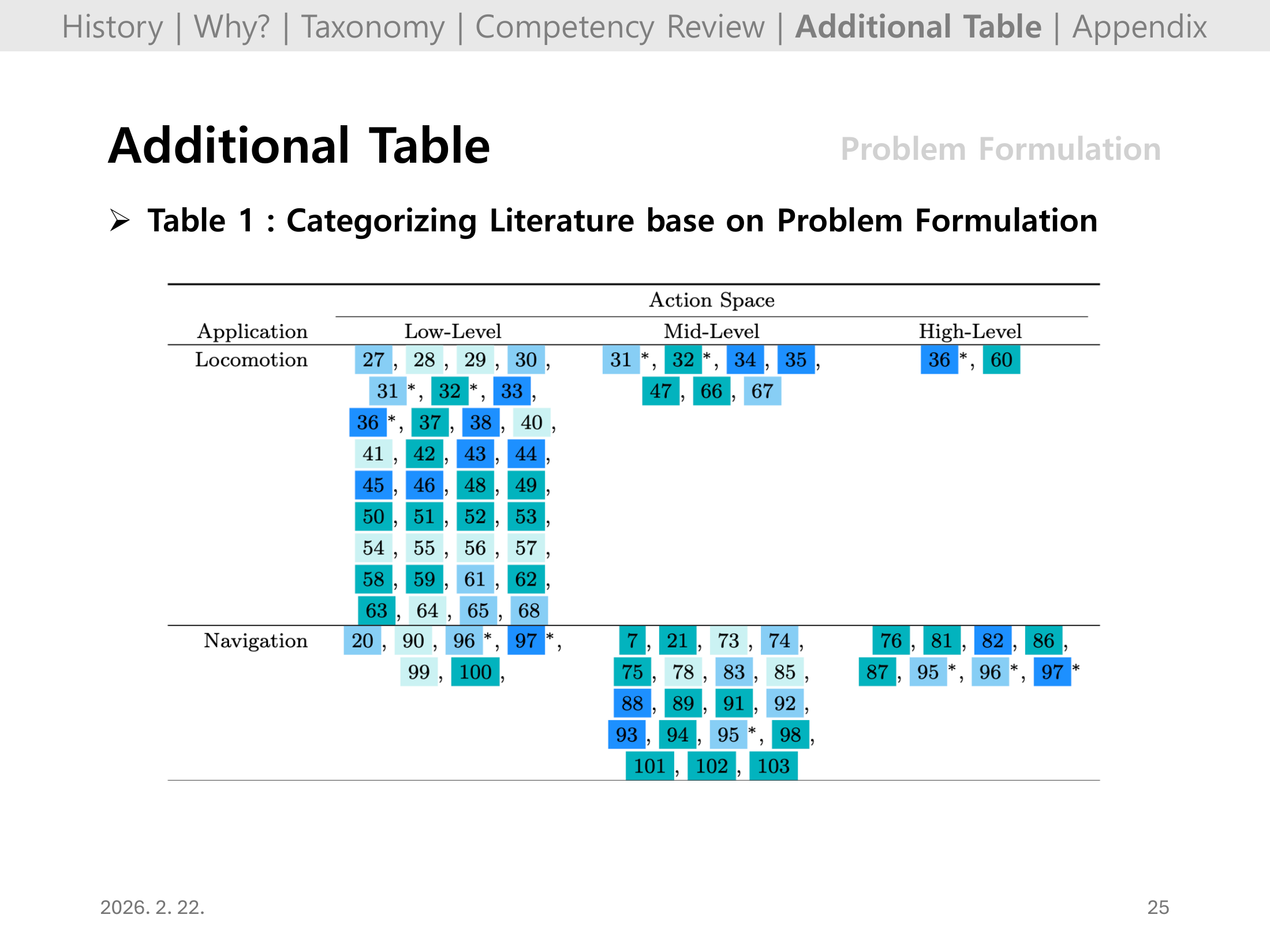
이 장은 논문의 Table 1을 통해 문제 공식화 축(action/observation/reward)을 기준으로 기존 문헌을 체계적으로 정렬한다.
즉, 어떤 과제에서 어떤 문제 정의가 많이 쓰였는지 한눈에 비교할 수 있는 참고 표다.
#Slide 26. Additional Table: Problem Formulation (Table 1, continued)
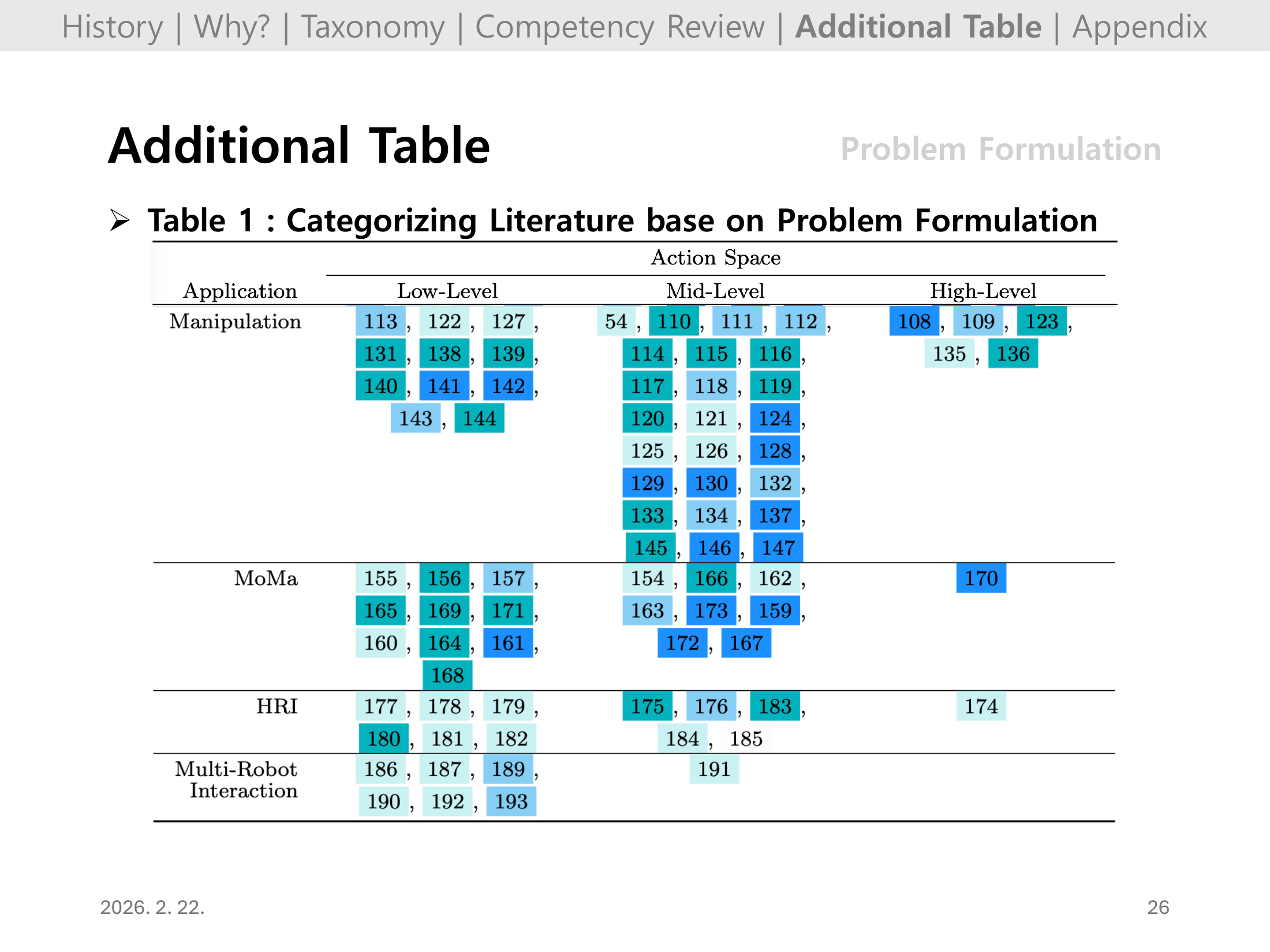
Slide 25의 연속 페이지로, 동일한 분류 기준을 더 많은 문헌에 확장해 보여준다.
발표 시에는 내 관심 과제와 유사한 문제 설정(보상/관측/행동공간)을 찾아 근거로 인용하기 좋다.
#Slide 27. Additional Table: Problem Formulation (Table 2)

Table 2에서는 다른 관점의 문제 공식화 분류를 보강해, domain 간 공통 패턴과 차이를 비교하게 해준다.
특히 어느 도메인이 sparse/dense reward에 의존하는지, 관측 차원이 어떻게 달라지는지 확인하는 용도로 유용하다.
#Slide 28. Additional Table: Problem Formulation (Table 2, continued)
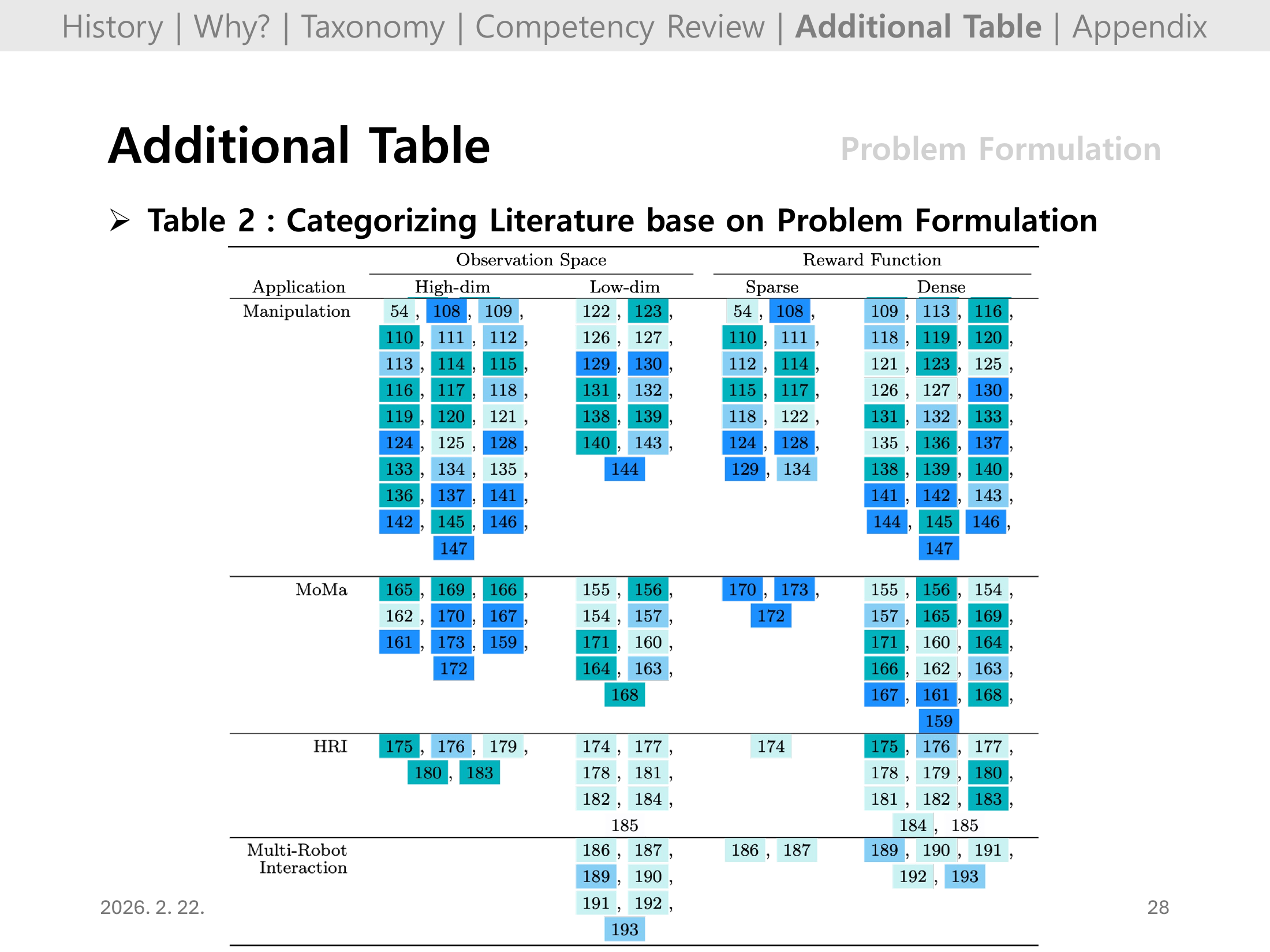
Slide 27의 연장으로, 표 기반 근거를 충분히 제시해 발표 결론의 신뢰도를 높이는 페이지다.
요약할 때는 “내가 선택한 태스크가 왜 해당 문제설정을 택해야 하는지”를 이 표와 연결하면 좋다.
#Slide 29. Additional Table: Solution Approach (Table 3)

Table 3는 solution approach(예: sim-to-real, model-free/model-based, policy optimization) 관점에서 문헌을 분류한다.
성공 사례가 어떤 학습 파이프라인 조합에서 주로 나왔는지 근거를 제시하는 핵심 부록 표다.
#Slide 30. Additional Table: Solution Approach (Table 3, continued)
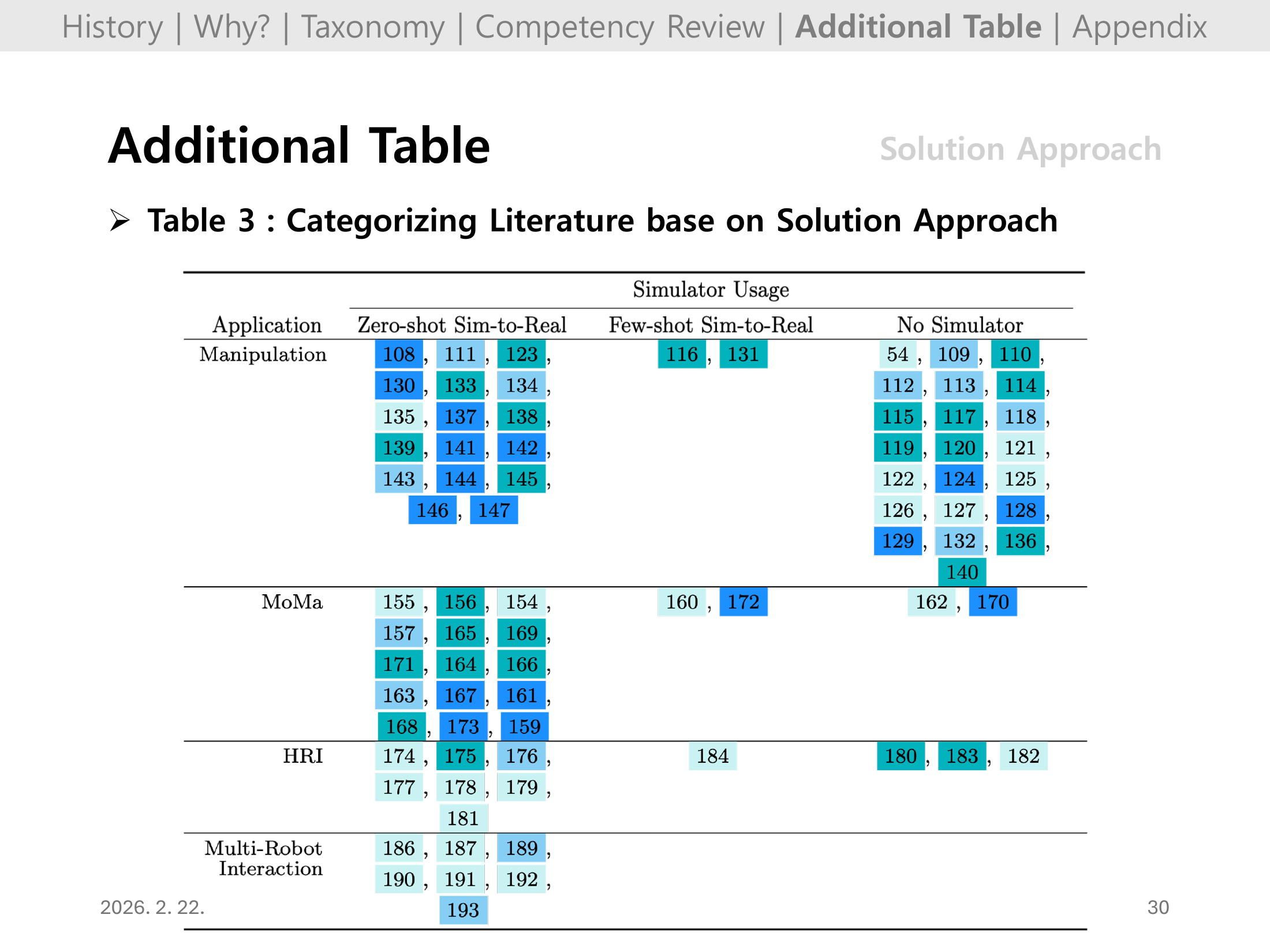
마지막 장은 solution approach 표의 연속으로, 리뷰 전체의 “방법론별 지형도”를 마무리한다.
내 결론에서는 이 표를 근거로, 다음 프로젝트에서 채택할 학습 전략(예: zero-shot sim-to-real vs real-world finetuning)을 명확히 제안하면 좋다.
#5) 내 결론 (초안)
- DRL의 실제 성공은 이미 존재하지만, 문제 유형에 따라 성숙도 편차가 매우 크다.
- 지금까지의 성공 공통점은 sim-to-real 가능 문제 + 정교한 엔지니어링(보상/도메인랜덤화/액션설계)이다.
- 앞으로의 승부처는 실세계 학습 안정화, 장기과업 통합, 사람/다중에이전트 상호작용 일반화다.
#6) 원문/발표/연구 기관 링크
- 논문(arXiv HTML): https://arxiv.org/html/2408.03539
- 논문(PDF): https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/chen_tang_ARCRAS2024.pdf
- 원래 발표 슬라이드(PDF): https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/chen_tang_ARCRAS2024.slides.pdf
- Learning Agents Research Group (LARG): https://www.cs.utexas.edu/~pstone/research.shtml
- Texas Robotics: https://robotics.utexas.edu
- RoBin Lab: https://robin-lab.cs.utexas.edu